Табеларно представљени подаци¶
У овој лекцији ћемо говорити о:
представљању табеларно задатих података помоћу листи у Пајтону,
ефикаснијем представљању табеларних података користећи библиотеку pandas,
визуелизацији табеларно представљених података, и
учитавање табела из локалних и удаљених ресурса.
Представљање табеларно задатих података помоћу листи¶
Најчешћи начин да организујемо велике количине података је да их представимо табелом. Рецимо, ова табела садржи податке о једној групи деце (при чему је, наравно, старост изражена у годинама, тежина у килограмима, а висина у центиметрима):
Ime |
Pol |
Starost |
Masa |
Visina |
|---|---|---|---|---|
Ana |
ž |
13 |
46 |
160 |
Bojan |
m |
14 |
52 |
165 |
Vlada |
m |
13 |
47 |
157 |
Gordana |
ž |
15 |
54 |
165 |
Dejan |
m |
15 |
56 |
163 |
Đorđe |
m |
13 |
45 |
159 |
Elena |
ž |
14 |
49 |
161 |
Žaklina |
ž |
15 |
52 |
164 |
Zoran |
m |
15 |
57 |
167 |
Ivana |
ž |
13 |
45 |
158 |
Jasna |
ž |
14 |
51 |
162 |
Да бисмо могли машински да обрађујемо и анализирамо податке прво их морамо представити у облику неке структуре података. Један једноставан начин да се то уради је да сваки ред табеле представимо једном листом, и да потом све те листе запакујемо у једну велику листу, рецимо овако:
In [1]: podaci = [["Ana", "ž", 13, 46, 160],
...: ["Bojan", "m", 14, 52, 165],
...: ["Vlada", "m", 13, 47, 157],
...: ["Gordana", "ž", 15, 54, 165],
...: ["Dejan", "m", 15, 56, 163],
...: ["Đorđe", "m", 13, 45, 159],
...: ["Elena", "ž", 14, 49, 161],
...: ["Žaklina", "ž", 15, 52, 164],
...: ["Zoran", "m", 15, 57, 167],
...: ["Ivana", "ž", 13, 45, 158],
...: ["Jasna", "ž", 14, 51, 162]]
...:
Из овако представљених података лако можемо добити податке о сваком појединачном детету у групи. Рецимо, податке о Дејану добијамо тако што испишемо елемент листе са индексом 4 (Пажња! Први елемент листе има индекс 0, зато подаци о Дејану који су наведени у 5. реду табеле имају индекс 4):
In [2]: podaci[4]
Out[2]: ['Dejan', 'm', 15, 56, 163]
Овај начин представљања података, међутим, није погодан за обраде по колонама. Рецимо, ако желимо да израчунамо просечну висину деце у групи морамо да пишемо програм. То није немогуће, чак није ни тешко, али је непрактично. Ево програма:
In [3]: sum = 0
...: for dete in podaci:
...: sum += dete[4]
...: float(sum) / len(podaci)
...:
Out[3]: 161.9090909090909
Програм ради на следећи начин:
прво помоћну променљиву
sumпоставимо на нулу (у њој ће се полако акумулирати збир висина све деце у групи);након тога циклус
for dete in podaci:прође кроз свако дете у групи (јер сваки елемент листеpodaciпредставља податке о једном детету) и на суму дода његову висину (висина детета се налази на петом месту у групи података за то дете, а то је елемент листе са индексом 4);коначно, добијени збир поделимо бројем података да бисмо израчунали просек.
Као што смо већ рекли, ово није јако тешко, али је непрактично. Треба нам флексибилнија структура података.
Библиотека pandas, структура података DataFrame и рад са колонама табеле¶
За ефикасно манипулисање табеларно представљеним подацима у Пајтону развијена је библиотека pandas. Њу можемо увести као што смо увозили и остале библиотеке (и уз пут ћемо јој дати надимак да бисмо мање морали да куцамо):
In [4]: import pandas as pd
Из ове библиотеке ћемо користити структуру података која се зове DataFrame (енгл. data значи „подаци”, frame значи „оквир”, тако да DataFrame значи „оквир са подацима”, односно „табела”).
Податке о деци сада лако можемо да препакујемо у DataFrame позивом функције са истим именом:
In [5]: tabela = pd.DataFrame(podaci)
Претходна команда није дала никакав излаз. Она је просто препаковала податке наведене у листи podaci у нову структуру података. Да бисмо се уверили да се ради само о препакивању, исписаћемо садржај променљиве tabela:
In [6]: tabela
Out[6]:
0 1 2 3 4
0 Ana ž 13 46 160
1 Bojan m 14 52 165
2 Vlada m 13 47 157
3 Gordana ž 15 54 165
4 Dejan m 15 56 163
5 Đorđe m 13 45 159
6 Elena ž 14 49 161
7 Žaklina ž 15 52 164
8 Zoran m 15 57 167
9 Ivana ž 13 45 158
10 Jasna ž 14 51 162
Ево и кратког видеа:

Да би табела била прегледнија, даћемо колонама име. Колонама се име даје овако:
In [7]: tabela = pd.DataFrame(podaci)
...: tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
...: tabela
...:
Out[7]:
Ime Pol Starost Masa Visina
0 Ana ž 13 46 160
1 Bojan m 14 52 165
2 Vlada m 13 47 157
3 Gordana ž 15 54 165
4 Dejan m 15 56 163
5 Đorđe m 13 45 159
6 Elena ž 14 49 161
7 Žaklina ž 15 52 164
8 Zoran m 15 57 167
9 Ivana ž 13 45 158
10 Jasna ž 14 51 162
Када свака колона има своје име, можемо да приступимо појединачним колонама:
In [8]: tabela["Ime"]
Out[8]:
0 Ana
1 Bojan
2 Vlada
3 Gordana
4 Dejan
5 Đorđe
6 Elena
7 Žaklina
8 Zoran
9 Ivana
10 Jasna
Name: Ime, dtype: object
In [9]: tabela["Visina"]
Out[9]:
0 160
1 165
2 157
3 165
4 163
5 159
6 161
7 164
8 167
9 158
10 162
Name: Visina, dtype: int64
Имена свих колона су увек доступна у облику листе овако:
In [10]: tabela.columns
Out[10]: Index(['Ime', 'Pol', 'Starost', 'Masa', 'Visina'], dtype='object')
Позивом једне од следећих функција лако можемо да вршимо елементарну анализу података који су представљени табелом:
sum– рачуна збир елемената у колони (сума);mean– рачуна просек елемената у колони (аритметичка средина се на енглеском каже arithmetic mean);median– рачуна медијану елемената у колони;min– рачуна вредност најмањег елемента у колони (минимум);max– рачуна вредност највећег елемента у колони (максимум).
На пример, висина најнижег детета у групи је:
In [11]: tabela["Visina"].min()
Out[11]: 157
Најстарије дете у групи има оволико година:
In [12]: tabela["Starost"].max()
Out[12]: 15
Просечна висина деце у групи је:
In [13]: tabela["Visina"].mean()
Out[13]: 161.9090909090909
Медијална висина:
In [14]: tabela["Visina"].median()
Out[14]: 162.0
Да ли цела група може да стане у лифт чија носивост је 600 кг?
In [15]: if tabela["Masa"].sum() <= 600:
....: print("Mogu svi da stanu u lift.")
....: else:
....: print("Ne. Zajedno su preteški.")
....:
Mogu svi da stanu u lift.
Визуелизација табеларно представљених података¶
Визуелизација података из табеле се своди на то да се одаберу интересантне колоне табеле и прикажу неком од техника које смо раније видели. Прво ћемо учитати одговарајућу библиотеку:
In [16]: import matplotlib.pyplot as plt
Ако желимо хистограмом да представимо висину деце у групи, одабраћемо колоне „Име” и „Висина” и приказати их, рецимо овако:
In [17]: plt.figure(figsize=(10,5))
....: plt.bar(tabela["Ime"], tabela["Visina"])
....: plt.title("Visina dece u grupi")
....: plt.show()
....:
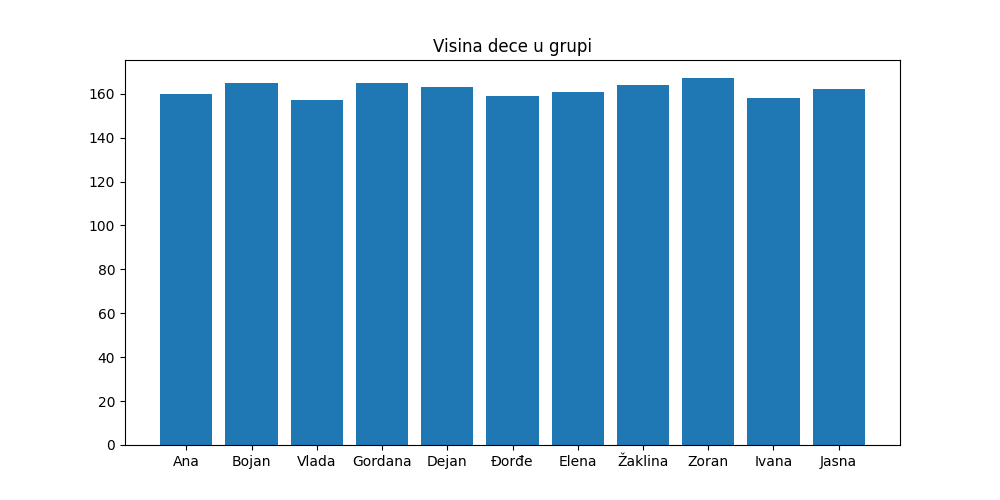
Као други пример представићемо тежину и старост деце у групи тако да тежина буде представљена црвеним стубићима, а старост зеленом. Приказаћемо и легенду да би било јасно шта која боја представља.
In [18]: plt.figure(figsize=(10,5))
....: plt.bar(tabela["Ime"], tabela["Masa"], color="r", label="Masa")
....: plt.bar(tabela["Ime"], tabela["Starost"], color="g", label="Starost")
....: plt.title("Starost i masa dece u grupi")
....: plt.legend()
....: plt.show()
....:
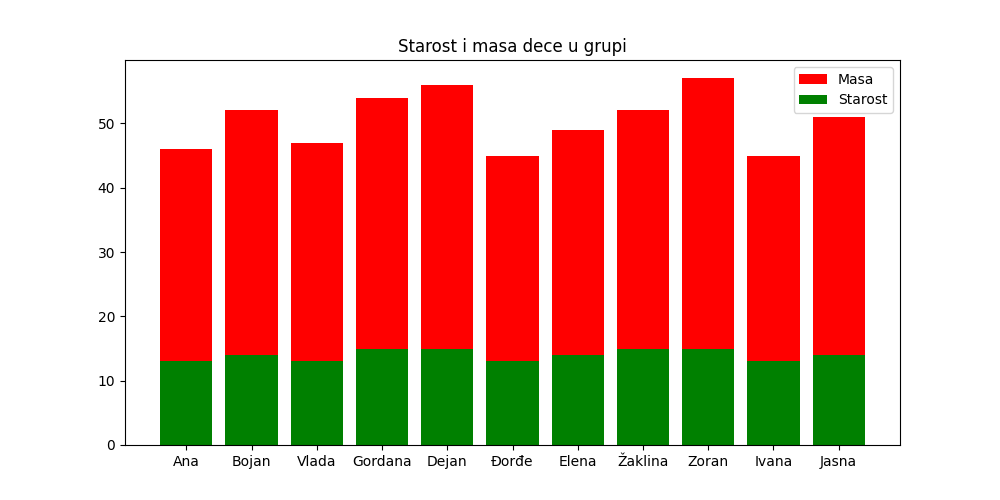
Ево и кратког видеа:
Учитавање података из локалних датотека и удаљених ресурса¶
Видели смо у претходним примерима да се најмукотрпнији посао обраде података састоји у томе да се подаци унесу у табелу. То је досадан посао који се често састоји у томе да се подаци просто прекуцају. Табеле са којима смо се сретали су зато биле веома мале. Модерна обрада података се, међутим, све више усмерава на анализу огромних количина података (енгл. big data) и ту прекуцавање података не долази у обзир.
Подаци се данас углавном прикупљају аутоматски, и програми за прикупљање података генеришу велике табеле података које после треба обрађивати. Постоје разни формати за табеларно представљање података, а најједноставнији од њих се зове CSV, (од енгл. comma separated values што значи „вредности раздвојене зарезима”).
CSV датотека је текстуална датотека у којој редови одговарају редовима табеле, а подаци унутар истог реда су раздвојени зарезима. На пример, датотека Top25YouTubers.csv садржи податке о о 25 најпопуларнијих Јутјубера према броју претплатника на дан 1.7.2019. Она изгледа овако:
RANK,GRADE,NAME,VIDEOS,SUBSCRIBERS,VIEWES
1,A++,T-Series,13629,105783888,76945588449
2,A,PewDiePie,3898,97853589,22298927681
3,A+,5-Minute Crafts,3341,58629572,14860695079
4,A++,Cocomelon - Nursery Rhymes,441,53163816,33519273951
...
25,A,TheEllenShow,10542,33362512,16519572219
Први ред табеле представља заглавље табеле које нам каже да табела има шест колона (RANK, GRADE, NAME, VIDEOS, SUBSCRIBERS, VIEWES). Врста
4,A++,Cocomelon - Nursery Rhymes,441,53163816,33519273951
значи да је на дан 1.7.2019. четврти по реду био Јутјуб канал са Јутјуб рангом А++ који се зове „Cocomelon - Nursery Rhymes” који је објавио укупно 441 видео на Јутјубу, који има 53.163.816 претплатника и 33.519.273.951 прегледа.
Библиотека pandas има функцију read_csv која учитава CSV датотеку и од ње прави табелу типа DataFrame.
Уколико се датотека налази на локалној машини, у фолдеру у коме се налази и Џупитер радна свеска из које јој приступамо, онда
се датотека учитава на следећи начин:
import pandas as pd
Top25 = pd.read_csv("Top25YouTubers.csv")
Учитавање података из локалних датотека је илустровано у следећем кратком видеу:
а провежбаћемо га на крају ове лекције, у склопу задатака које треба урадити у Џупитер радној свесци.
С друге стране, иста та датотека се налази и на следећем линку:
Библиотека pandas омогућује да се подаци преузму и са удаљених ресурса без потребе да се они прво пребаце на локалну
машину. Да бисмо приступили податку који се налази на некој другој машини потребно је да обе машине имају приступ Интернету и да знамо тачну локацију податка на удаљеној машини. Тачна локација било ког ресурса на Интернету је описана његовим URL-ом (од енгл. Universal Resource Locator, што значи „Универзални локатор ресурса”).
Ево примера:
In [19]: import pandas as pd
....: Top25 = pd.read_csv("https://petljamediastorage.blob.core.windows.net/root/Media/Default/Kursevi/informatika_VIII/podaci/Top25YouTubers.csv")
....:
Прикажимо првих неколико редова ове табеле. Функција head(N) приказује првих N редова табеле (енгл. head значи „глава”). Ако функцију позовемо без броја она ће приказати првих пет редова:
In [20]: Top25.head()
Out[20]:
RANK GRADE NAME VIDEOS SUBSCRIBERS VIEWES
0 1 A++ T-Series 13629 105783888 76945588449
1 2 A PewDiePie 3898 97853589 22298927681
2 3 A+ 5-Minute Crafts 3341 58629572 14860695079
3 4 A++ Cocomelon - Nursery Rhymes 441 53163816 33519273951
4 5 A++ SET India 31923 51784081 36464793233
In [21]: Top25.head(10)
Out[21]:
RANK GRADE NAME VIDEOS SUBSCRIBERS VIEWES
0 1 A++ T-Series 13629 105783888 76945588449
1 2 A PewDiePie 3898 97853589 22298927681
2 3 A+ 5-Minute Crafts 3341 58629572 14860695079
3 4 A++ Cocomelon - Nursery Rhymes 441 53163816 33519273951
4 5 A++ SET India 31923 51784081 36464793233
5 6 A+ Canal KondZilla 1100 50560964 25446405744
6 7 A+ WWE 42404 46098586 34085586984
7 8 B+ Justin Bieber 134 45873439 625649566
8 9 A Dude Perfect 209 43796634 8354321862
9 10 A+ Badabun 4406 41131131 13175713909
Функција tail(N) приказује последњих N редова табеле, односно, последњих пет редова ако је позвемо без аргумента (енгл. tail значи „реп”):
In [22]: Top25.tail()
Out[22]:
RANK GRADE NAME VIDEOS SUBSCRIBERS VIEWES
20 21 B- Katy Perry 97 34416819 361332307
21 22 A Felipe Neto 1872 33549096 7458531306
22 23 A JustinBieberVEVO 122 33514535 18873475304
23 24 A Fernanfloo 534 33378699 7201866552
24 25 A TheEllenShow 10542 33362512 16519572219
In [23]: Top25.tail(7)
Out[23]:
RANK GRADE NAME VIDEOS SUBSCRIBERS VIEWES
18 19 A- elrubiusOMG 809 35324033 7772447040
19 20 B Taylor Swift 166 34920060 255089844
20 21 B- Katy Perry 97 34416819 361332307
21 22 A Felipe Neto 1872 33549096 7458531306
22 23 A JustinBieberVEVO 122 33514535 18873475304
23 24 A Fernanfloo 534 33378699 7201866552
24 25 A TheEllenShow 10542 33362512 16519572219
Прикажимо податке о броју претплатника стубичастим дијаграмом:
In [24]: plt.figure(figsize=(15,10))
....: plt.bar(Top25["NAME"], Top25["SUBSCRIBERS"])
....: plt.title("Top 25 YouTube kanala prema broju pretplatnika")
....: plt.show()
....:
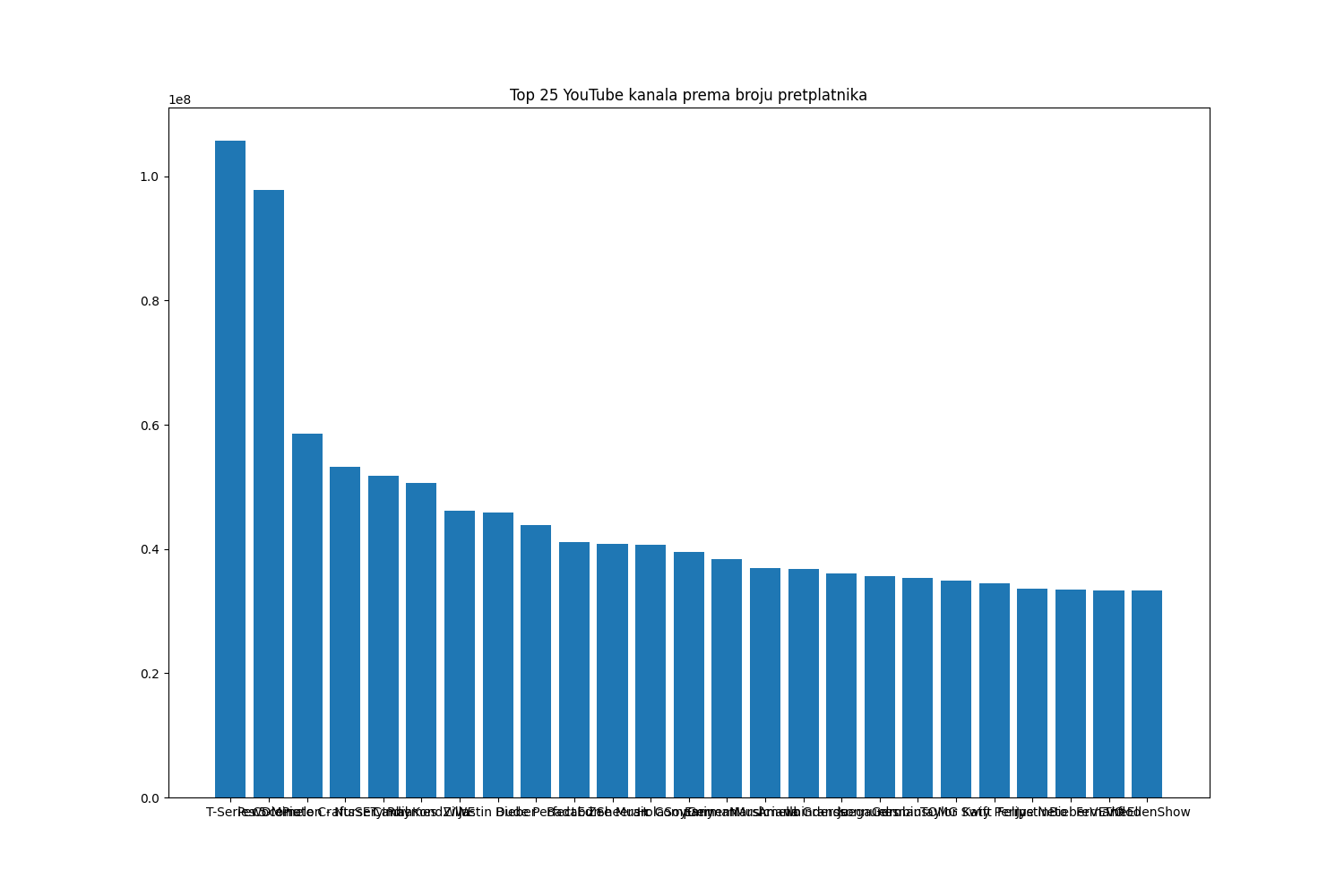
Пошто су имена канала веома дугачка на хоризонталној оси се ништа не види. Зато ћемо уместо функције bar позвати функцију barh која ради исти посао, али стубиће исцртава хоризонтално:
In [25]: plt.figure(figsize=(10,10))
....: plt.barh(Top25["NAME"], Top25["SUBSCRIBERS"])
....: plt.title("Top 25 YouTube kanala prema broju pretplatnika")
....: plt.show()
....:
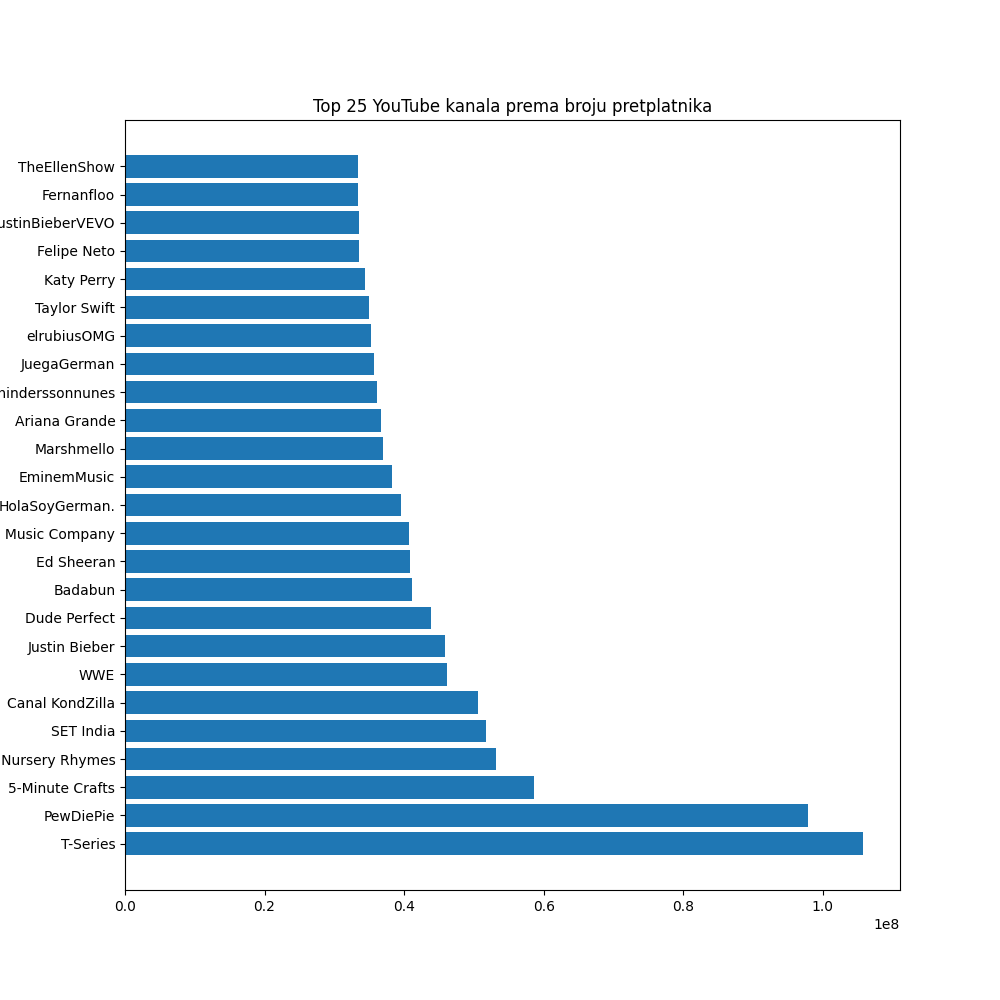
Пример.¶
На адреси
https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv
се налази јавно доступан списак свих држава на свету. Ову табелу можемо лако учитати наредбом read_csv:
In [26]: drzave = pd.read_csv("https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv")
....: drzave.head(10)
....:
Out[26]:
Country Region
0 Algeria AFRICA
1 Angola AFRICA
2 Benin AFRICA
3 Botswana AFRICA
4 Burkina AFRICA
5 Burundi AFRICA
6 Cameroon AFRICA
7 Cape Verde AFRICA
8 Central African Republic AFRICA
9 Chad AFRICA
Помоћу наредбе read_html може се прочитати и табела директно из HTML кода неке веб странице. Рецимо, следећа наредба чита списак свих федералних јединица Сједињених Америчких Држава са одговарајуће странице Википедије:
In [27]: US = pd.read_html("https://simple.wikipedia.org/wiki/List_of_U.S._states", header=[0,1])[0]
На веб страни коју читамо може бити више табела и зато функција read_html враћа листу табела. Табела коју желимо да видимо је прва на наведеној страни и зато иза наредбе следи конструкт [0]. Аргумент header=[0,1] значи да прве две врсте треба узети за заглавље табеле. Ево како изгледа табела:
In [28]: US.head()
Out[28]:
Name &postal abbs. [1] Unnamed: 2_level_0 ... Water area[4] Numberof Reps.
Name &postal abbs. [1] Name &postal abbs. [1].1 Unnamed: 2_level_1 ... mi2 km2 Numberof Reps.
0 Alabama NaN AL ... 1775 4597 7
1 Alaska NaN AK ... 94743 245384 1
2 Arizona NaN AZ ... 396 1026 9
3 Arkansas NaN AR ... 1143 2961 4
4 California NaN CA ... 7916 20501 53
[5 rows x 14 columns]
Ево и кратке видео илустрације:
Задаци¶
За вежбу покрени Џупитер окружење и реши задатке из радне свеске J06.ipynb