Модификације табеле и записивање табеле у датотеку¶
У овој лекцији ћемо говорити о: 1. додавању нове врсте или колоне табели; и 2. записивању табеле у датотеку.
Додавање нове врсте или колоне табели¶
Понекад је важно да вредности које смо израчунали на основу података у табели (на пример, просеке оцена по ученицима) и сачувамо у табели. Ако табела нема за то предвиђену колону или врсту лако је можемо додати!
Вратимо се поново на пример са оценама ученика кога смо видели на раније:
In [1]: import pandas as pd
...: razred = [["Ana", 5, 3, 5, 2, 4, 5],
...: ["Bojan", 5, 5, 5, 5, 5, 5],
...: ["Vlada", 4, 5, 3, 4, 5, 4],
...: ["Gordana", 5, 5, 5, 5, 5, 5],
...: ["Dejan", 3, 4, 2, 3, 3, 4],
...: ["Đorđe", 4, 5, 3, 4, 5, 4],
...: ["Elena", 3, 3, 3, 4, 2, 3],
...: ["Žaklina", 5, 5, 4, 5, 4, 5],
...: ["Zoran", 4, 5, 4, 4, 3, 5],
...: ["Ivana", 2, 2, 2, 2, 2, 5],
...: ["Jasna", 3, 4, 5, 4, 5, 5]]
...: ocene = pd.DataFrame(razred)
...: ocene.columns=["Ime", "Informatika", "Engleski", "Matematika", "Fizika", "Hemija", "Likovno"]
...: ocene1 = ocene.set_index("Ime")
...: ocene1
...:
Out[1]:
Informatika Engleski Matematika Fizika Hemija Likovno
Ime
Ana 5 3 5 2 4 5
Bojan 5 5 5 5 5 5
Vlada 4 5 3 4 5 4
Gordana 5 5 5 5 5 5
Dejan 3 4 2 3 3 4
Đorđe 4 5 3 4 5 4
Elena 3 3 3 4 2 3
Žaklina 5 5 4 5 4 5
Zoran 4 5 4 4 3 5
Ivana 2 2 2 2 2 5
Jasna 3 4 5 4 5 5
Овде смо прво увезли библиотеку pandas са скраћеним именом „pd”, од листе података смо направили табелу, дали колонама имена и индексирали смо табелу по имену ученика.
Као што смо раније видели, лако можемо да израчунамо просек оцена сваког ученика и да те податке испишемо. Међутим, ако желимо да просеке запамтимо у табели, треба нам нова колона. Нова колона се табели додаје тако што се просто напише:
In [2]: ocene1["ProsekUc"] = 0.0
Ако покушамо да непостојећој колони додамо неку вредност, систем ће сам на крај табеле додати нову колону и попунити је наведеним вредностима:
In [3]: ocene1
Out[3]:
Informatika Engleski Matematika Fizika Hemija Likovno ProsekUc
Ime
Ana 5 3 5 2 4 5 0.0
Bojan 5 5 5 5 5 5 0.0
Vlada 4 5 3 4 5 4 0.0
Gordana 5 5 5 5 5 5 0.0
Dejan 3 4 2 3 3 4 0.0
Đorđe 4 5 3 4 5 4 0.0
Elena 3 3 3 4 2 3 0.0
Žaklina 5 5 4 5 4 5 0.0
Zoran 4 5 4 4 3 5 0.0
Ivana 2 2 2 2 2 5 0.0
Jasna 3 4 5 4 5 5 0.0
Сада ћемо у једном for-циклусу да прођемо кроз индексну колону табеле и да за сваки ред табеле израчунамо просек бројева уписаних у колоне „Informatika”–„Likovno”. (Не смемо да рачунамо просек целог реда, јер редови сада садрже и колону „ProsekUc” која не сме да се укључи у рачун просека!)
In [4]: for ucenik in ocene1.index:
...: ocene1.loc[ucenik, "ProsekUc"] = ocene1.loc[ucenik, "Informatika":"Likovno"].mean()
...:
Ево како изгледа нова табела:
In [5]: ocene1
Out[5]:
Informatika Engleski Matematika Fizika Hemija Likovno ProsekUc
Ime
Ana 5 3 5 2 4 5 4.000000
Bojan 5 5 5 5 5 5 5.000000
Vlada 4 5 3 4 5 4 4.166667
Gordana 5 5 5 5 5 5 5.000000
Dejan 3 4 2 3 3 4 3.166667
Đorđe 4 5 3 4 5 4 4.166667
Elena 3 3 3 4 2 3 3.000000
Žaklina 5 5 4 5 4 5 4.666667
Zoran 4 5 4 4 3 5 4.166667
Ivana 2 2 2 2 2 5 2.500000
Jasna 3 4 5 4 5 5 4.333333
Да бисмо израчунали просечну оцену за сваки предмет, додаћемо нову врсту:
In [6]: ocene1.loc["ProsekPr"] = 0.0
...: ocene1
...:
Out[6]:
Informatika Engleski Matematika Fizika Hemija Likovno ProsekUc
Ime
Ana 5.0 3.0 5.0 2.0 4.0 5.0 4.000000
Bojan 5.0 5.0 5.0 5.0 5.0 5.0 5.000000
Vlada 4.0 5.0 3.0 4.0 5.0 4.0 4.166667
Gordana 5.0 5.0 5.0 5.0 5.0 5.0 5.000000
Dejan 3.0 4.0 2.0 3.0 3.0 4.0 3.166667
Đorđe 4.0 5.0 3.0 4.0 5.0 4.0 4.166667
Elena 3.0 3.0 3.0 4.0 2.0 3.0 3.000000
Žaklina 5.0 5.0 4.0 5.0 4.0 5.0 4.666667
Zoran 4.0 5.0 4.0 4.0 3.0 5.0 4.166667
Ivana 2.0 2.0 2.0 2.0 2.0 5.0 2.500000
Jasna 3.0 4.0 5.0 4.0 5.0 5.0 4.333333
ProsekPr 0.0 0.0 0.0 0.0 0.0 0.0 0.000000
Овде треба да застанемо за тренутак и да се подсетимо да се запис облика ocene1["ProsekUc"] односи на колоне табеле тако да ће наредба
ocene1["ProsekUc"] = 0.0
додати нову колону попуњену нулама, док се запис ocene1.loc["ProsekPr"] односи на врсте табеле, па ће наредба
ocene1.loc["ProsekPr"] = 0.0
додати нову врсту попуњену нулама (што се и десило у примеру).
In [7]: for predmet in ocene1.columns:
...: ocene1.loc["ProsekPr", predmet] = ocene1.loc["Ana":"Jasna", predmet].mean()
...: ocene1
...:
Out[7]:
Informatika Engleski Matematika Fizika Hemija Likovno ProsekUc
Ime
Ana 5.000000 3.000000 5.000000 2.000000 4.000000 5.000000 4.000000
Bojan 5.000000 5.000000 5.000000 5.000000 5.000000 5.000000 5.000000
Vlada 4.000000 5.000000 3.000000 4.000000 5.000000 4.000000 4.166667
Gordana 5.000000 5.000000 5.000000 5.000000 5.000000 5.000000 5.000000
Dejan 3.000000 4.000000 2.000000 3.000000 3.000000 4.000000 3.166667
Đorđe 4.000000 5.000000 3.000000 4.000000 5.000000 4.000000 4.166667
Elena 3.000000 3.000000 3.000000 4.000000 2.000000 3.000000 3.000000
Žaklina 5.000000 5.000000 4.000000 5.000000 4.000000 5.000000 4.666667
Zoran 4.000000 5.000000 4.000000 4.000000 3.000000 5.000000 4.166667
Ivana 2.000000 2.000000 2.000000 2.000000 2.000000 5.000000 2.500000
Jasna 3.000000 4.000000 5.000000 4.000000 5.000000 5.000000 4.333333
ProsekPr 3.909091 4.181818 3.727273 3.818182 3.909091 4.545455 4.015152
Ево још једног примера. На следећем линку:
се налази датотека StanovnistvoSrbije2017.csv која садржи процену броја становника Републике Србије по годинама на дан 31.12.2017. Први ред табеле представља заглавље табеле које нам каже да табела има три колоне (Старост, Мушко, Женско). Прво ћемо учитати табелу и индексирати је колоном „Старост”:
In [8]: stanovnistvo = pd.read_csv("https://petljamediastorage.blob.core.windows.net/root/Media/Default/Kursevi/informatika_VIII/podaci/StanovnistvoSrbije2017.csv")
...: stanovnistvo1 = stanovnistvo.set_index("Старост")
...:
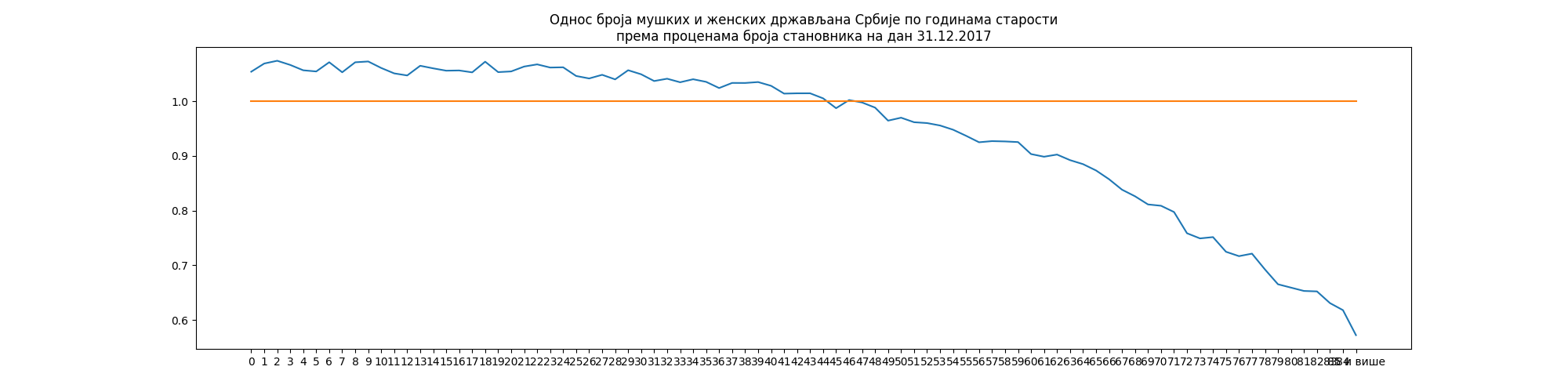
Сада ћемо урадити малу демографску анализу: израчунаћемо однос броја мушкараца и жена по годинама старости и приказаћемо податке линијским дијаграмом.
Прво ћемо табели додати нову колону „М/Ж” и у ту колону уписати израчунате односе:
In [9]: stanovnistvo1["М/Ж"] = 0.0
...: for i in stanovnistvo1.index:
...: stanovnistvo1.loc[i, "М/Ж"] = stanovnistvo1.loc[i, "Мушко"] / stanovnistvo1.loc[i, "Женско"]
...:
Ево првих неколико редова табеле:
In [10]: stanovnistvo1.head(10)
Out[10]:
Мушко Женско М/Ж
Старост
0 33145 31444 1.054096
1 33252 31105 1.069024
2 33807 31475 1.074091
3 34076 31952 1.066475
4 33436 31643 1.056663
5 34278 32505 1.054545
6 33773 31523 1.071376
7 33892 32185 1.053037
8 34706 32396 1.071305
9 34519 32177 1.072785
Потом ћемо приказати дијаграм коме ћемо додати линију на висини 1.0 да бисмо лакше уочили у ком тренутку број мушкараца постаје мањи од броја жена:
In [11]: import matplotlib.pyplot as plt
....: plt.figure(figsize=(20,5))
....: plt.plot(stanovnistvo1.index, stanovnistvo1["М/Ж"])
....: plt.plot(stanovnistvo1.index, [1.0] * len(stanovnistvo1.index))
....: plt.title("Однос броја мушких и женских држављана Србије по годинама старости\nпрема проценама броја становника на дан 31.12.2017")
....: plt.show()
....:
Записивање табеле у датотеку¶
Веома је важно омогућити да се подаци који су учитани из неке датотеке могу, након обраде, поново уписати у датотеку. Да ова могућност не постоји морали бисмо сваки пут изнова вршити обраду података, што у неким случајевима може да буде веома дуготрајан посао.
Табела се уписује у датотеку типа CSV позивом функције to_csv (енгл. „у csv”). На пример, табелу stanovnistvo1 смо модификовали тако што смо јој додали нову колону у коју смо уписали однос броја мушкараца и жена по узрастима. Ако желимо да тако модификовану табелу сачувамо под новим именом, то можемо учинити овако:
stanovnistvo1.to_csv("podaci/StanovnistvoSrbije2017-Novo.csv", encoding="utf-8")
Први податак који се прослеђује функцији to_csv представља име нове датотеке у коју ће бити уписани подаци, док аргумент encoding="utf-8" значи да ће подаци бити уписани у датотеку користећи систем за кодирање који се зове UTF-8. Ово морамо да наведемо зато што у табели имамо податке који су записани ћирилицом. Чак и да смо користили латиницу морали бисмо да користимо UTF-8 систем за кодирање због слова као што су č, ć, š, ž, đ, а која не постоје у енглеском алфабету. Аргумент encoding="utf-8" можемо да изоставимо само ако знамо да су за записивање података у табели коришћени искључиво симболи из енглеског алфабета.
Ево примера. Са следећег линка
https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv
ћемо учитати списак држава на свету и записаћемо ту табелу (без икаквих трансформација) у локалну датотеку drzavesveta.csv у фолдеру podaci:
drzave = pd.read_csv("https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv")
drzave.to_csv("podaci/drzavesveta.csv")
Ако сада из неког програма за уређивање текста (рецимо, Notepad) погледамо датотеку коју смо добили записивањем, видећемо да она изгледа овако (наведено је само првих неколико редова):
,Country,Region
0,Algeria,AFRICA
1,Angola,AFRICA
2,Benin,AFRICA
3,Botswana,AFRICA
4,Burkina,AFRICA
5,Burundi,AFRICA
6,Cameroon,AFRICA
7,Cape Verde,AFRICA
8,Central African Republic,AFRICA
9,Chad,AFRICA
(итд)
Приликом уписивања података у табелу Пајтон је уписао и индексну колону. Код табеле stanovnistvo1 нам је то одговарало јер је табела била индексирана колоном „Старост”. Овде нам то, ипак, не одговара зато што индексна колона не даје никакву важну информацију о подацима у табели. Ако желимо да упижемо табелу у датотеку, али тако да се индексна колона не уписује, можемо то урадити овако:
drzave.to_csv("podaci/drzavesveta.csv", index=False)
Сада у датотеци пише:
Country,Region
Algeria,AFRICA
Angola,AFRICA
Benin,AFRICA
Botswana,AFRICA
Burkina,AFRICA
Burundi,AFRICA
Cameroon,AFRICA
Cape Verde,AFRICA
Central African Republic,AFRICA
Chad,AFRICA
(итд)
што смо и желели.
Ево и кратке видео илустрације:

Задаци¶
За вежбу покрени Џупитер окружење и реши задатке из радне свеске J08.ipynb