Сортирање, филтрирање и фреквенцијска анализа¶
У овој лекцији ћемо говорити о:
преуређивању редова табеле како би се поређали по величини по неком критеријуму (сортирање);
издвајању редова табеле који задовољавају неке услове (филтрирање); и
бројању редова табеле који имају неке особине (фреквенцијска анализа).
Сортирање података¶
Сортирати податке значи поређати их по величини. Да бисмо видели како се то ради у библиотеци pandas прво ћемо учитати библиотеку:
In [1]: import pandas as pd
а онда ћемо направити табелу са подацима о групи деце коју смо већ користили, колонама ћемо дати одговарајућа имена и индексираћемо табелу именима деце:
In [2]: podaci = [["Ana", "ž", 13, 46, 160],
...: ["Bojan", "m", 14, 52, 165],
...: ["Vlada", "m", 13, 47, 157],
...: ["Gordana", "ž", 15, 54, 165],
...: ["Dejan", "m", 15, 56, 163],
...: ["Đorđe", "m", 13, 45, 159],
...: ["Elena", "ž", 14, 49, 161],
...: ["Žaklina", "ž", 15, 52, 164],
...: ["Zoran", "m", 15, 57, 167],
...: ["Ivana", "ž", 13, 45, 158],
...: ["Jasna", "ž", 14, 51, 162]]
...: tabela = pd.DataFrame(podaci)
...: tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
...: tabela1 = tabela.set_index("Ime")
...:
Ево како табела изгледа:
In [3]: tabela1
Out[3]:
Pol Starost Masa Visina
Ime
Ana ž 13 46 160
Bojan m 14 52 165
Vlada m 13 47 157
Gordana ž 15 54 165
Dejan m 15 56 163
Đorđe m 13 45 159
Elena ž 14 49 161
Žaklina ž 15 52 164
Zoran m 15 57 167
Ivana ž 13 45 158
Jasna ž 14 51 162
Хајде сада да сортирамо табелу по висини употребом функције sort_values (енгл. sort значи „сортирај, поређај по величини”, док values значи „вредности”).
Овој функцији морамо да кажемо по ком критеријуму се сортирају подаци (по висини, тежини, старости, …) тако што име одговарајуће колоне наведемо као вредност аргумента by (енгл. реч „by” значи свашта, али у овом контексту значи „према”).
Функција не мења полазну табелу, већ од ње прави нову:
In [4]: tabela1_po_visini = tabela1.sort_values(by="Visina")
...: tabela1_po_visini
...:
Out[4]:
Pol Starost Masa Visina
Ime
Vlada m 13 47 157
Ivana ž 13 45 158
Đorđe m 13 45 159
Ana ž 13 46 160
Elena ž 14 49 161
Jasna ž 14 51 162
Dejan m 15 56 163
Žaklina ž 15 52 164
Bojan m 14 52 165
Gordana ž 15 54 165
Zoran m 15 57 167
Пошто нисмо навели како желимо да сортирамо податке (од најмањег ка највећем, или обрнуто) подаци су сортирани од најмањег ка највећем. Уколико желимо да сортирамо табелу по висини, али од највеће ка најмањој, потребно је то нагласити користећи параметар ascending=False (енгл. ascending значи „растуће”).
In [5]: tabela1_po_visini = tabela1.sort_values(by="Visina", ascending=False)
...: tabela1_po_visini
...:
Out[5]:
Pol Starost Masa Visina
Ime
Zoran m 15 57 167
Bojan m 14 52 165
Gordana ž 15 54 165
Žaklina ž 15 52 164
Dejan m 15 56 163
Jasna ž 14 51 162
Elena ž 14 49 161
Ana ž 13 46 160
Đorđe m 13 45 159
Ivana ž 13 45 158
Vlada m 13 47 157
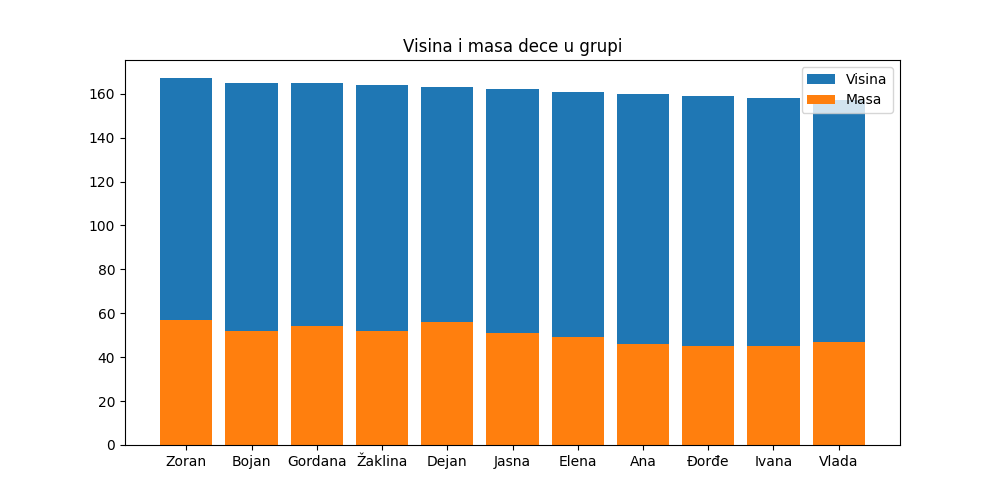
Хајде, за крај, да прикажемо податке из овако сортиране табеле.
In [6]: import matplotlib.pyplot as plt
...: plt.figure(figsize=(10,5))
...: plt.bar(tabela1_po_visini.index, tabela1_po_visini["Visina"], label="Visina")
...: plt.bar(tabela1_po_visini.index, tabela1_po_visini["Masa"], label="Masa")
...: plt.title("Visina i masa dece u grupi")
...: plt.legend()
...: plt.show()
...:
Ево и кратке видео илустрације:

Филтрирање података¶
Често је из табеле потребно издвојити редове који имају неке особине. На пример, ако желимо да издвојимо само оне редове табеле у којима су наведени подаци о девојчицама, то можемо урадити на следећи начин:
tabela1[tabela1.Pol == "ž"]
Овај израз ће из табеле tabela1 издвојити све редове код којих у колони „Pol” пише „ž”. (Обратите пажњу на то да се приликом формирања критеријума у изразу tabela1.Pol не пишу наводници! Не питајте зашто…)
In [7]: devojke = tabela1[tabela1.Pol == "ž"]
...: devojke
...:
Out[7]:
Pol Starost Masa Visina
Ime
Ana ž 13 46 160
Gordana ž 15 54 165
Elena ž 14 49 161
Žaklina ž 15 52 164
Ivana ž 13 45 158
Jasna ž 14 51 162
На сличан начин можемо да издвојимо сву децу која имају преко 50 кг:
In [8]: preko_50kg = tabela1[tabela1.Masa > 50]
...: preko_50kg
...:
Out[8]:
Pol Starost Masa Visina
Ime
Bojan m 14 52 165
Gordana ž 15 54 165
Dejan m 15 56 163
Žaklina ž 15 52 164
Zoran m 15 57 167
Jasna ž 14 51 162
Критеријуме можемо и да комбинујемо. На пример, ако желимо да из табеле извучемо податке о свим дечацима са највише 55 кг треба из табеле да издвојимо податке који задовољавају два критеријума:
Masa <= 55 и Pol == "m".
Логички везник „и” се у библиотеци pandas означава симболом &. Према томе, податке добијамо тако што табели проследимо следећи захтев за филтрирање:
In [9]: decaci_do_55kg = tabela1[(tabela1.Masa <= 55) & (tabela1.Pol == "m")]
...: decaci_do_55kg
...:
Out[9]:
Pol Starost Masa Visina
Ime
Bojan m 14 52 165
Vlada m 13 47 157
Đorđe m 13 45 159
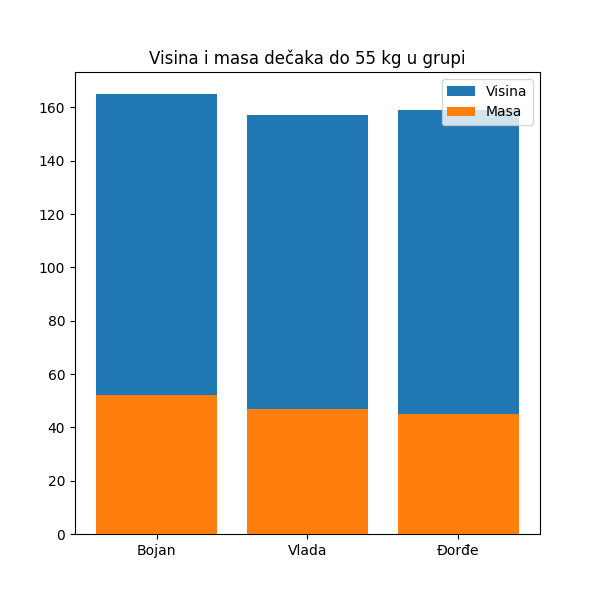
Приказаћемо, за крај, податке о маси и висини ових дечака једним графиконом:
In [10]: plt.figure(figsize=(6,6))
....: plt.bar(decaci_do_55kg.index, decaci_do_55kg["Visina"], label="Visina")
....: plt.bar(decaci_do_55kg.index, decaci_do_55kg["Masa"], label="Masa")
....: plt.title("Visina i masa dečaka do 55 kg u grupi")
....: plt.legend()
....: plt.show()
....:
Ево и кратке видео илустрације:
Фреквенцијска анализа¶
Да се подсетимо, фреквенцијска анализа низа података се своди на то да се преброји колико се пута који податак појављује у низу. Док смо раније морали доста тога сами да урадимо, библиотека pandas има функцију value_counts која врши фреквенцијску анализу (енгл. value значи „вредност”, док count значи „бројати”; дакле, пребројати вредности).
Ево примера. Ако у табели са којом радимо желимо да пребројимо дечаке и девојчице, то можемо учинити позивом функције value_counts овако:
In [11]: tabela1["Pol"].value_counts()
Out[11]:
ž 6
m 5
Name: Pol, dtype: int64
Функција value_counts је у колони „Pol” пребројала све вредности и утврдила да се у тој колони вредност „ž” појављује 6 пута, док се вредност „m” појављује 5 пута.
Ако желимо да утврдимо старосну структуру групе, применићемо функцију value_counts на колону „Starost”:
In [12]: tabela1["Starost"].value_counts()
Out[12]:
13 4
15 4
14 3
Name: Starost, dtype: int64
Функција value_counts је у колони „Starost” пребројала све вредности и утврдила да се у тој колони вредности 15 и 13 појављују по 4 пута, док се вредност 14 појављује 3 пута.
Ако резултат рада функције value_counts сместимо у променљиву:
In [13]: frekv = tabela1["Pol"].value_counts()
....: frekv
....:
Out[13]:
ž 6
m 5
Name: Pol, dtype: int64
онда можемо лако да реконструишемо које су вредности уочене у табели, и које су њихове фреквенције. Наиме,
frekv.index
нам даје листу уочених вредности, док
frekv.values
даје њихове фреквенције.
In [14]: print("Vrednosti koje se javljaju u koloni:", frekv.index)
....: print("Njihove frekvencije:", frekv.values)
....:
Vrednosti koje se javljaju u koloni: Index(['ž', 'm'], dtype='object')
Njihove frekvencije: [6 5]
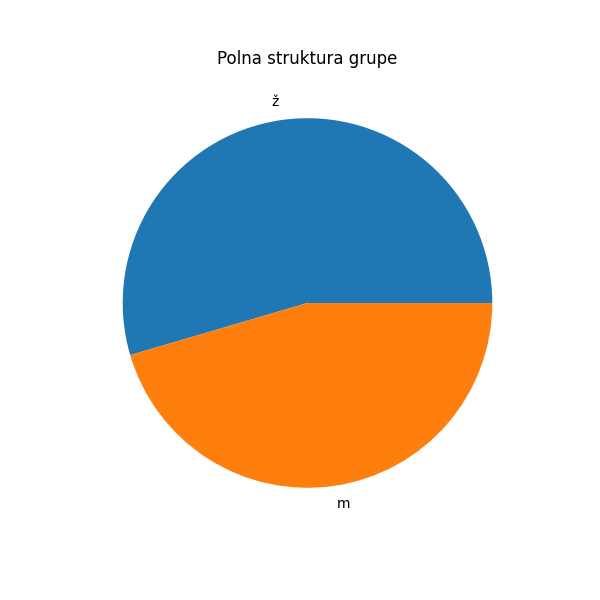
Полну структуру ове групе деце можемо да прикажемо секторским дијаграмом овако:
In [15]: import matplotlib.pyplot as plt
....: frekv = tabela1["Pol"].value_counts()
....: plt.figure(figsize=(6,6))
....: plt.pie(frekv.values, labels=frekv.index)
....: plt.title("Polna struktura grupe")
....: plt.show()
....:
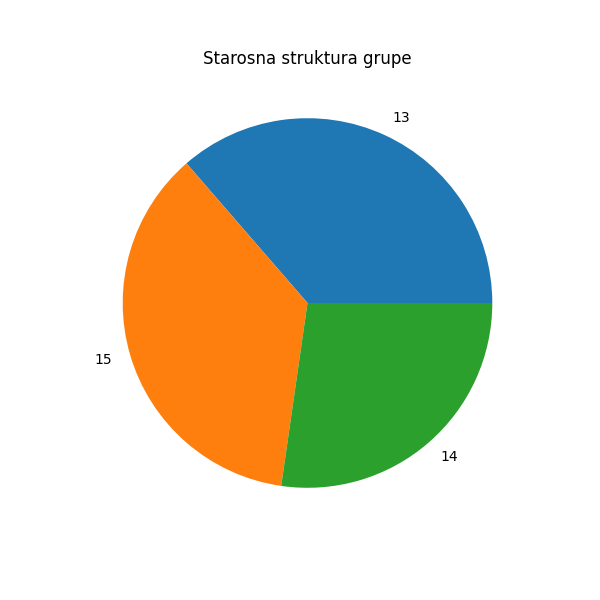
На сличан начин можемо да прикажемо старосну структуру групе:
In [16]: frekv = tabela1["Starost"].value_counts()
....: plt.figure(figsize=(6,6))
....: plt.pie(frekv.values, labels=frekv.index)
....: plt.title("Starosna struktura grupe")
....: plt.show()
....:
Следе две кратке видео илустрације:
На адреси
https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv
се налази јавно доступан списак свих држава на свету. Ову табелу можемо лако учитати наредбом read_csv:
In [17]: drzave = pd.read_csv("https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv")
....: drzave.head(5)
....:
Out[17]:
Country Region
0 Algeria AFRICA
1 Angola AFRICA
2 Benin AFRICA
3 Botswana AFRICA
4 Burkina AFRICA
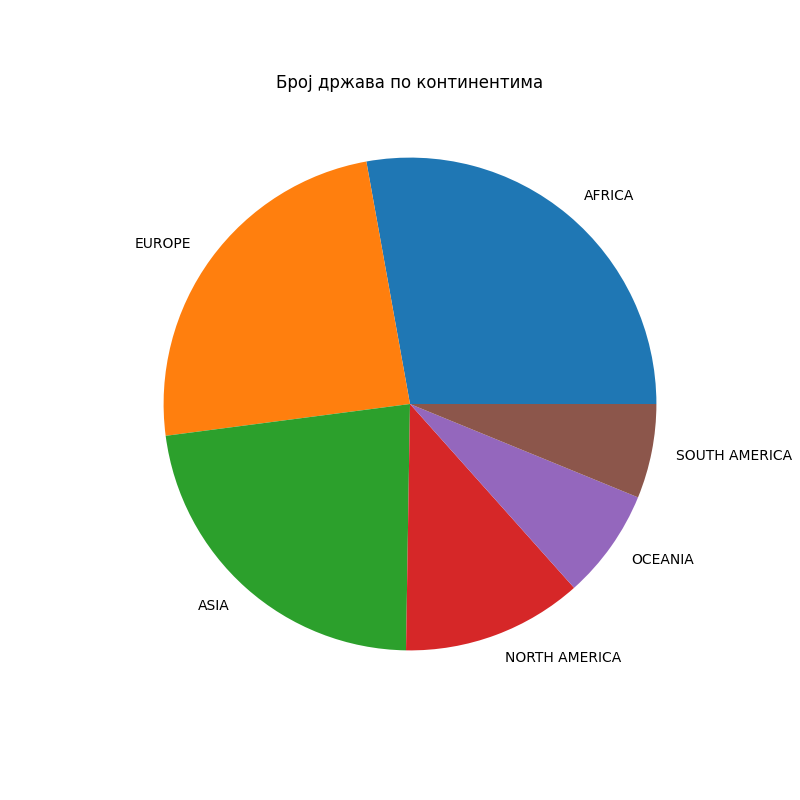
Број држава по континентима можемо видети овако:
In [18]: drzave["Region"].value_counts()
Out[18]:
AFRICA 54
EUROPE 47
ASIA 44
NORTH AMERICA 23
OCEANIA 14
SOUTH AMERICA 12
Name: Region, dtype: int64
Прикажимо број држава по континентима секторским дијаграмом:
In [19]: import matplotlib.pyplot as plt
....: po_kontinentima = drzave["Region"].value_counts()
....: plt.figure(figsize=(8,8))
....: plt.pie(po_kontinentima.values, labels=po_kontinentima.index)
....: plt.title("Број држава по континентима")
....: plt.show()
....:
Задаци¶
За вежбу покрени Џупитер окружење и реши задатке из радне свеске J09.ipynb