Вишеструка линеарна регресија¶
У уводној причи о скуповима података видели смо да се користи већи број атрибута. Ипак, у причи о линеарној регресији смо користили само један атрибут (квадратуру некретнине). Вероватно се питаш шта радимо када имамо више атрибута и да ли тада можемо да применимо модел линеарне регресије.
Модел линеарне регресије који је прилагођен овом сценарију се зове вишеструка линеарна регресија и има облик \(y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \beta_3X_3 + … + \beta_nX_n\). Немој да те овај дугачки израз збуни - сада вредности \(X_1\), \(X_2\), \(X_3\), …, \(X_n\) представљају појединачне атрибуте а параметри \(\beta_0\), \(\beta_1\), \(\beta_2\), \(\beta_3\), …, \(\beta_n\) параметре модела. Иза овог уопштавања је опет идеја о линеарној зависности између појединачних атрибута и циљне променљиве.
Циљ учења је да одредимо вредности параметара \(\beta_0\), \(\beta_1\), \(\beta_2\), \(\beta_3\), …, \(\beta_n\) и тако стекнемо представу о зависностима. До њих долазимо на исти начин као и код линеарне регресије коју смо упознали (за њу кажемо и да је проста): минимизацијом средњеквадратне грешке на скупу података за тренирање. Техника градијентног спуста се може уопштити тако да одговара и овој поставци задатка и може нам помоћи да нађемо баш скуп вредности \(\beta_0\), \(\beta_1\), \(\beta_2\), \(\beta_3\), …, \(\beta_n\) за који је средњеквадратна грешка најмања.
У случају модела линеарне регресије са једним атрибутом могли смо да замислимо и смисао који носе параметри \(\beta_0\) и \(\beta_1\): одређивали су померај и нагиб праве која пролази кроз скуп података. Тако су нам указивали на јачину линеарне зависност између улазне и излазне променљиве, тј. на то колико се вредност излазне променљиве \(y\) промени када атрибут \(x\) променимо за 1. Сада, када имамо више параметара, природно је да се питамо какво значење можемо да им дамо. Па, и они моделују исту врсту зависности. Ако замислимо да су само \(\beta_0\) и \(\beta_2\): параметри који су различити од нуле, онда је веза између циљне променљиве \(y\) и атрибута \(x_2\) представљена једначином \(y = \beta_0 + \beta_2x_2\), тј. линеарна и исто нам указује колико ће се променити вредност за циљну променљиву \(y\) и у ком смеру када вредност за \(x_2\) променимо за 1.
С обзиром на то да параметри за нас сумирају знања из скупа података, у случају вишеструке линеарне регресије, веће вредности параметара указују на већи значај неког атрибута на вредност циљне променљиве. Да бисмо могли да испратимо ово својство, вредности израчунатих параметара обично исцртавамо графиконом са стубићима. На доњој слици приказане су вредности параметара једног модела који користи реални скуп података за предвиђање цена некретнина (популарни Бостон скуп података о некретнинама). Без много улажења у детаље овог скупа, одмах можемо приметити да атрибут LSTAT утиче највише, и то негативно, на вредност циљне променљиве, док атрибути RM и RAD имају позитиван утицај, и то скоро подједнако. Графике овог типа, који могу да нам дају неку идеју о утицају атрибута, називамо графицима важности атрибута (енг. feature importance graph).
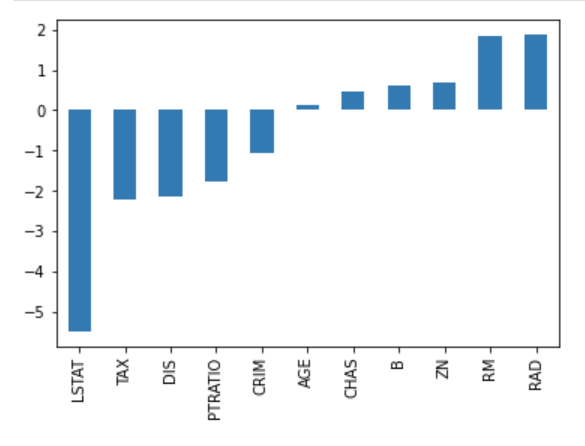
График важности атрибута вишеструке регресије
Још један детаљ који треба на нагласимо, да те касније не би изненадио, тиче се линеарности. Модел линеарне регресије је линеаран по параметрима. То значи да би се и модел чији је облик \(y = \beta_0 + \beta_1X + \beta_2X^2 + \beta_3X^3\), у којем фигуришу степени вредности атрибута, водио као линеарни модел. Слично је и за модел \(y = \beta_0 + \beta_1log(X)\), у којем фигурише логаритам вредности атрибута. О овим можда неочекиваним улогама атрибута можеш да размишљаш као трансформацијама које поправљају линеарну зависност између атрибута и циљне променљиве.