Алгоритам к-најближих суседа¶

Поменули смо да постоје и непараметарски модели машинског учења. Модел који се добија применом алгоритма к-најближих суседа је баш такав. Откријмо како он функционише!
Нека се наш скуп за обучавање састоји од парова бројева \((x_1, x_2)\) и одговарајућих имена класа. Парове можемо да прикажемо као тачке у равни где прва координата \(x_1\) означава вредност на x-оси, а друга координата \(x_2\) вредност на y-оси. У пракси вредности \(x_1\) и \(x_2\) увек вежемо за неке конкретне атрибуте, на пример, температуру и влажност ваздуха, али сада о њима можемо да размишљамо као о неким уопштеним вредностима. Нека сваки од парова бројева припада једној од двеју класа: црвеним троугловима или плавим квадратима. Како имамо само две класе, закључујеш да је реч о бинарној класификацији. Замисли сада да зелени круг представља нову инстанцу, нови пар бројева, за који треба да одредимо којој класи припада: да ли је то црвени троугао или плави квадрат.
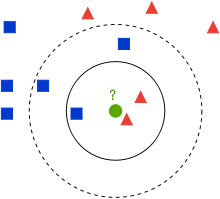
Скуп за обучавање
Алгоритам к-најближих суседа је алгоритам класификације који каже да прво фиксирамо број суседа (околних инстанци) к на неку конкретну вредност и да затим одредимо колико међу к-најближих суседа има црвених и плавих: црвени сусед је инстанца која припада црвеној класи, а плави сусед инстанца који припада плавој класи. Ако, на пример, број к фиксирамо на вредност 3, три најближа суседа зеленог круга се налазе унутар пуне кружнице. То су два црвена троугла и један плави квадрат.
Даље, алгоритам к-најближих суседа каже да нову инстанцу, тј. нови пар тачака, придружујемо класи бројнијег суседа: ако су црвени суседи бројнији, за нову инстанцу ћемо рећи да припада црвеној класи и, слично, ако су плави суседи бројнији, за нову инстанцу ћемо рећи да припада плавој класи. Овај вид закључивања можеш да разумеш и као изреку ”с ким си, такав си” у свету машинског учења.
У нашем примеру, када је вредност броја к фиксирана на 3, закључићемо да зелени круг треба да придружимо црвеној класи јер имамо два црвена суседа и једног плавог.
Хајде да видимо шта ће се догодити ако броја к фиксирамо на вредност 5. На слици је ово суседство приказано испрекиданом кружницом. Како се сада ту налазе три плава квадрата и два црвена троугла, закључак би био да зелени круг треба да придружимо плавој класи.

Ова секција је упарена са Jupyter свеском 07-algoritam_k-najblizih_suseda.ipynb.
Да би могао да пратиш садржај даље, кликни на линк, а потом и на дугме  да би се садржај отворио у окружењу Google Colab.
Уколико свеске прегледаш на локалној машини, међу садржајима пронађи свеску са истим именом и покрени је. За детаљније инструкције
погледај секцију Hands-on зона и лекцију Jupyter свеске за вежбу.
да би се садржај отворио у окружењу Google Colab.
Уколико свеске прегледаш на локалној машини, међу садржајима пронађи свеску са истим именом и покрени је. За детаљније инструкције
погледај секцију Hands-on зона и лекцију Jupyter свеске за вежбу.
Пратећи материјал садржи поменути скуп тачака и апликацију у којој можеш да испиташ шта ће се догодити ако одабереш неку другу вредност броја к. С обзиром на то да алгоритам треба да одлучи којих суседа има више, мудро је да бираш непарне вредности броја к.
Приметимо да осим од броја суседа к, резултат алгоритма зависи и од начина на који меримо удаљености до суседа! Да бисмо пронашли најближе суседе, морамо некако да измеримо растојање до њих.
До сада смо се на часовима математике сусретали са растојањем које се зове еуклидско. Подсетимо се, еуклидско растојање између тачака \(А\) и \(В\) се рачуна као дужина дужи која спаја тачке \(А\) и \(B\). На пример, за тачке \(А=(0, 0)\) и \(В=(3, 4)\) еуклидско растојање се рачуна као \(\sqrt{(3-0)^2 + (4-0)^2}=5\)
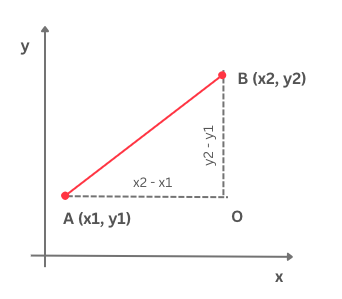
Еуклидско растојање
Постоје и многа друга растојања. На пример, може ти бити заниљиво Менхетн растојање. За разлику од еуклидског растојања које рачуна ”хипотенузу” троугла одређеног тачкама \(А\) и \(B\) и \(O\) (ако пратимо претходну слику), Менхетн растојање рачуна збир ”катета” овог троугла. За тачке \(А\) и \(B\) вредност Менхетн растојања би износила \(|3-0| + |4-0| = 7\).
Које растојање ћемо одабрати зависи од природе задатка и смисла који имају атрибути са којима радимо. У општем случају можемо да опробамо више растојања и одаберемо оно за које добијамо најбоље резултате. О томе ћемо још говорити у наставку. Важно је нагласити да функција мора да задовољава нека одређена математичка својства да би је прогласили растојањем па зато не може баш свака функција да нам буде од помоћи.
Баш као и други алгоритми машинског учења, алгоритам к-најближих суседа се обучава над скупом за тренирање. Занимљиво је приметити да се фаза учења у овом алгоритму заправо своди само на чување скупа података. У другим алгоритмима, као што је линеарна регресија или логистичка регресија, видели смо да се у овој фази израчунавају вредности неких параметара који се појављују у моделу тако што се тражи минимум функције грешке. Алгоритам к-најближих суседа није такав. Пресликавање које учимо није одређено неком конкретном функцијом већ самим подацима и корацима које треба да спроведемо. Зато је уобичајено да моделе који имају ово својство зовемо непараметарским моделима.
Алгоритам к-најближих суседа цео посао реализује у току примене, тј. одлучивања о томе којој класи припада нова инстанца. Када треба класификовати нову инстанцу, прво израчунамо растојање нове инстанце од свих инстанци у скупу података за тренирање. Затим сортирамо ова растојања од најмањег до највећег. Прва к растојања задржавамо (јер су то растојања до к најближих суседа) и бирамо инстанце из скупа за тренирање на које се односе. Даље пратимо шта се догађа у простору њихових обележја и тражимо најбројније обележје, тј. најбројнију класу. Као што смо видели у уводном примеру, нову инстанцу треба да придружимо класи која је најбројнија.
Овај алгоритам је једноставно и имплементирати па засучимо рукаве и почнимо!
Замислићемо да радимо са скупом података који смо до сада користили и да свака инстанца има облик (\(x_1\), \(x_2\), \(obelezje\)) где је \(obelezje\) вредност 0 за црвену боју или 1 за плаву.
За мерење растојања између инстанци користићемо функцију euklidsko_rastojanje, која је дефинисана следећим блоком кода:
def euklidsko_rastojanje(instanca1, instanca2):
return np.sqrt((instanca1[0]-instanca2[0])**2 + (instanca1[1]-instanca2[1])**2)
Сам алгоритам к-најближих суседа је представљен следећим блоком кода:
def kNN(k, instance, nova_instanca, klase={0:'crvena', 1: 'plava'}):
# prvo izracunavamo rastojanja izmedju nove instance i svih instanci u skupu podataka
rastojanja = [euklidsko_rastojanje(instanca, nova_instanca) for instanca in instance]
# potom sortiramo rastojanja, izdvajamo k najmanjih i instance kojima odgovaraju
# proglasavamo susedima
susedi = np.argsort(rastojanja)[0:k]
# zatim ocitavamo obelezja suseda i prebrojavamo ih
obelezja_suseda = [instance[sused][2] for sused in susedi]
prebrojavanja_obelezja = np.bincount(obelezja_suseda)
# obelezje nove instance ce biti obelezje najbrojnijeg suseda
klasa = np.argmax(prebrojavanja_obelezja)
return klase[klasa]
У њему, као што смо дискутовали, спроводимо следеће кораке:
израчунавамо растојање од нове инстанце до свих инстанци у скупу података,
затим сортирамо растојања и издвајамо к најмањих,
инстанце којима одговарају издвојена растојања проглашавамо суседима,
у скупу издвојених суседа пребројавамо најбројније,
закључујемо да нова инстанца припада класи најбројнијег суседа.
Функцију kNN можеш да пробаш у пратећој свесци. На енглеском језику се алгоритам к-најближих суседа зове k-nearest-neighbours па се често сусреће
скраћено име k-NN. Отуда и име функције.
Остало је још да научимо како то да одаберемо баш најбољу вредност броја к. О томе ћемо говорити у следећој лекцији.

Да ли алгоритам к-најближих суседа може да се примени у задацима вишекласне класификације?
Да, само ће бити више различитих суседа па морамо да будемо пажљивији приликом пребројавања.
Да ли алгоритам к-најближих суседа може да се примени у регресионим задацима?
Да. Само ће сада вредности циљне променљиве најближих суседа бити неке реалне вредности па нема много смисла да их пребројавамо и тражимо најчешће. Треба да урадимо нешто што је смислено за задатак регресије, рецимо да упросечимо (израчунамо аритметичку средину) све вредности.