Неуронске мреже¶

У овој лекцији ћемо упознати неуронске мреже, посебну групу алгоритама машинског учења. Њима дугујемо многе занимљиве пробоје у свету вештачке интелигенције.
Са часова биологије ти је познато да је ћелија основна јединица грађе и функције свих живих бића. Из угла вештачке интелигенције и учења, најзанимљивије су нам ћелије мозга. Оне се зову неурони. Неурони се састоје из тела у којем је језгро и дужих и краћих наставака, који се зову аксони и дендрити. Наставци неуронима омогућавају да се повежу са другим неуронима. Те тачке повезивања неурона се називају синапсама. Оне омогућавају да се сигнали, тј. електрични импулси који генерише један неурон, пренесу до другог неурона. Занимљиво је да један неурон може бити повезан са милионима других неурона. То значи да он прима и обрађује сигнале који стижу од мноштва других неурона и на основу својих интерних механизама фино прорачунава сигнал који даље шаље другим неуронима. Уобичајено је да се ово стање назива стање активације неурона. Оно траје тек делић секунде, али омогућава да се изврше суптилне калкулације и генерише сигнал који се преноси кроз цео нервни систем.
Слика преузета са freepik.com¶
Неурон који сусрећемо у вештачкој интелигенцији је математичка апстракција неурона мозга. Њега описујемо функцијом више променљивих \(f(x_1, x_2, ..., x_n)\), где свака од променљивих \(x_1\), \(x_2\), …, \(x_n\) одговара по једном сигналу који стиже до неурона. Како нису сви сигнали подједнако важни за активности неурона, придружују им се тежине \(w_1\), \(w_2\), …, \(w_n\) које треба да укажу на њихов значај. Веће вредности ових бројева указују да је сигнал важнији, а мање вредности да је сигнал мање важан. Тако, укупна стимулација неурона одговара тежинској суми \(w_1x_1 + w_2x_2 + ... + w_nx_n\). Да би могло да се утиче на додатна понашања неурона, овој суми се додаје и један слободан члан \(b\), тако да укупна стимулација неурона заправо износи \(w_1x_1 + w_2x_2 + ... + w_nx_n + b\). Она се даље прослеђује такозваној активационој функцији \(\varphi\), која има задатак да израчуна излаз неурона. У зависности од избора активационе функције зависиће и вредности излаза које се добијају. Ако сада све систематично запишемо, добијамо да је за примљене сигнале \(x_1\), \(x_2\), …, \(x_n\) излаз неурона \(y = \varphi(w_1x_1 + w_2x_2 + ... + w_nx_n + b)\). Поступак који смо описали можеш да испратиш и на доњој илустрацији.
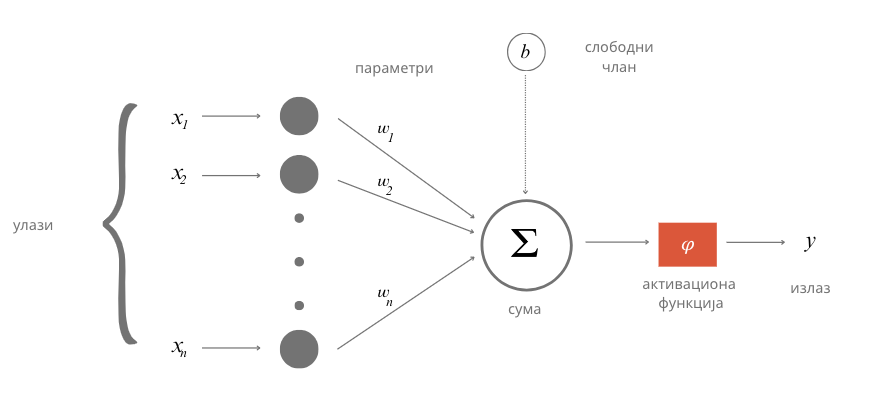
Математичка апстракција неурона

Приближимо додатно смисао параметра \(b\). Природни неурон карактерише такозвани праг активације - уколико је укупан сигнал који неурон прими већи од вредности прага активације, он се активира, обрађује сигнал и прослеђује резултат обраде даље другим неуронима. Сличну улогу у математичком моделу неурона има и параметар \(b\). Уколико је укупни сигнал већи од прага активације \(b\), тј. ако је \(w_1x_1 + w_2x_2 + ... + w_nx_n > b\), неурон ће се активирати. Стога нам параметар \(b\) оставља могућност да утичемо на додатна понашања неурона. Израз \(w_1x_1 + w_2x_2 + ... + w_nx_n > b\) се може записати и као \(w_1x_1 + w_2x_2 + ... + w_nx_n - b > 0\) па је у том смислу параметар \(b\) и саставни део суме.
Када неуроне повежемо међу собом, добијамо неуронску мрежу (енг. neural network). Неуронска мрежа се по правилу састоји од слојева (енг. layer), посебно удружених група неурона.
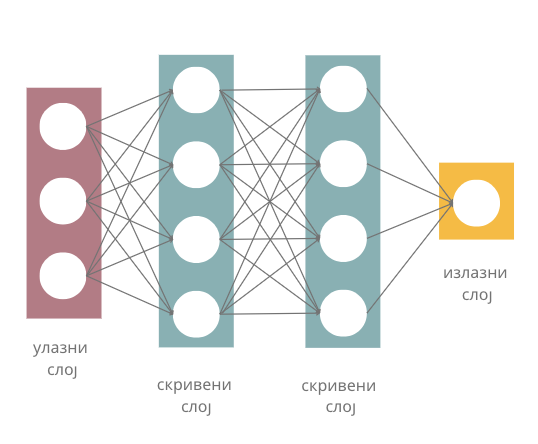
Слојеви неуронске мреже
Улазни слој (енг. input layer) је слој који се налази на улазу неуронске мреже. Улазне сигнале \(x_1\), \(x_2\), …, \(x_n\) овог слоја повезујемо са вредностима атрибута које имамо у скупу података и тако прилазимо практичној примени неуронских мрежа. На пример, ако располажемо скупом података у којем се налазе три атрибута, температура, влажност ваздуха и атмосферски притисак, улазни слој ће имати три неурона: први ће одговарати првом атрибуту, температури, други ће одговарати другом атрибуту, влажности ваздуха, а трећи неурон трећем атрибуту, тј. атмосферском притиску. За једну конкретну инстанцу скупа података са вредностима температуре, влажности ваздуха и атмосферског притиска који износе, редом, 19℃, 77% и 1011,2 mb имаћемо вредности сигнала \(x_1=19\), \(x_2=77\) и \(x_3=1011,2\). У духу претходне приче, први неурон улазног слоја прима и обрађује само сигнал \(x_1\) и то тако што га пропушта без било какве модификације (то је могуће за избор активационе функције \(\varphi(x)=x\) и вредност \(w_1=1\) и \(b=0\)). Слично важи и за преостала два неурона и њихове сигнале \(x_2\) и \(x_3\). То би значило да нам улазни слој омогућава да подаци уђу у мрежу.
Излазни слој (енг. output layer) је слој који се налази на излазу неуронске мреже. Као што наслућујеш, он нам омогућава да очитамо резултате које је неуронска мрежа израчунала за нас. У зависности од задатка који се решава, зависиће и број неурона који се налази у овом слоју.

- 1
- Одговор је тачан.
- 3
- Одговор није тачан.
- 5
- Одговор није тачан.
Q-5: Шта мислиш, ако користимо неуронску мрежу за задатак регресије, колико неурона имамо у излазном слоју?
У задацима регресије, пошто очекујемо једну бројчану вредност као резултат (количину падавина или нешто слично), довољан нам је један неурон. Његов излаз треба да одговара предикцији коју очекујемо. За задатак класификације размотримо посебно бинарну класификацију и вишекласну класификацију. Како код бинарне класификације очекујемо две вредности, 0 или 1, можда ће ти прва помисао бити да су нам потребна два неурона. Ипак, ако боље размислиш, приметићеш да је довољан чак и један неурон: ако његов излаз пређе неки праг, неку унапред дефинисану вредност, то можемо водити као резултат 1, или, у супротном, као резултат 0. У случају вишекласне класификације можемо да имамо више класа па је практично да за сваку класу уведемо по један неурон.

Колико је неурона у излазном слоју потребно у задатку класификације слика цифара?
Одговор:
Сложићеш се да у задатку вишекласне класификације очекујемо да сви излази неурона излазног слоја буду 0, осим једног који има вредност 1 - тако ћемо тачно знати о којој је класи реч.
Слојеве неуронске мреже који се налазе између улазног и излазног слоја називамо скривеним слојевима (енг. hidden layers). Уобичајено је да се неуронске мреже које имају више од једног скривеног слоја називају дубоким неуронским мрежама (енг. deep neural networks). Одатле долази и име дубоко учењe (енг. deep learning) за област машинског учења која их изучава и име плитко учење (енг. shallow learning) за класичније форме учења.
Потпуно повезане неуонске мреже (енг. fully connected neural networks) су мреже код којих је сваки неурон претходног слоја повезан за сваким неуроном наредног слоја. Слика на којој су приказани слојеви неуронске мреже приказује и једну потпуно повезану неуронску мрежу јер су сви неурони улазног слоја повезани са свим неуронима првог скривеног слоја, затим су сви неурони првог скривеног слоја повезани са свим неуронима другог скривеног слоја, и на крају, сви неурони другог скривеног слоја су повезани са свим неуронима (на нашој слици само једним) излазног слоја. Начини на који су неурони слојева повезани између себе одређује архитектуру неуронских мрежа и нека специфична својства мрежа која даље одређују у којим областима могу да се користе. У наредној лекцији упознаћемо неке такве типове.
Размотримо сада шта смо заправо добили увођењем неурона и неуронских мрежа. Претпоставимо да имамо три атрибута \(x_1\), \(x_2\) и \(x_3\). Линеарну зависност између атрибута и циљне променљиве смо математички описивали једначином \(y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_3\). Уколико уместо параметара \(\beta\) запишемо \(w\) а уместо \(\beta_0\) запишемо \(b\) и пребацимо га на крај, добијамо заправо тежинску суму \(w_1x_1 + w_2x_2 + w_3x_3 + b\) коју израчунава један неурон за сигнале које прима. То значи да, када не би било активационе функције \(\varphi\) и неурон би моделовао линеарну зависност између атрибута (сигнала) и излаза. Ово можемо графички приказати и мрежом која се састоји само од улазног слоја са три неурона и излазног слоја са једним неуроном, као на доњој слици.
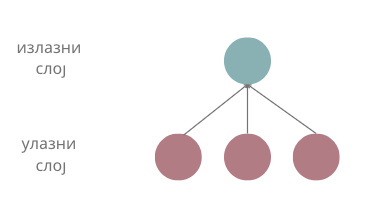
Ако активациона функција не би постојала, да ли би из угла моделовања зависности нешто променило додавање новог скривеног слоја? Нека то буде слој жуте боје на следећој слици.
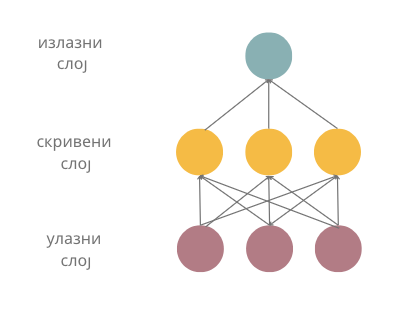
Сада сваки неурон скривеног слоја израчунава неку линеарну комбинацију атрибута, а неурон излазног слоја неку линеарну комбинацију вредности скривеног слоја. То би значило да наш неурон излазног слоја опет израчунава неку линеарну комбинацију атрибута и да се нисмо много померили од представљања неких сложенијих зависности између атрибута и излаза. Додатно, не бисмо се померили чак ни додавањем 100 скривених слојева - увек бисмо моделовали линеарну зависност.
Зато укључивање активационе функције у израчунавања неурона значајно мења скуп могућности које имамо. Уколико искористимо неку нелинеарну активациону функцију, моћи ћемо да моделујемо и неке нелинеарне зависности између атрибута и циљне променљиве. Тако постојање нелинеарне активационе функције у скривеном слоју из претходног примера омогућава да неурон излазног слоја сада израчунава неку нелинеарну комбинацију атрибута. У овом светлу, додавање нових слојева има много више смисла. Комбинујући нелинеарности већег броја слојева можемо да моделујемо комплексне зависности између атрибута и излаза.
Да би се све коцкице уклопиле, остаје још да продискутујемо које су то нелинеарне активационе функције које су популарне у машинском учењу. То су сигмоидна функција коју смо упознали у причи о логистичкој регресији, хиперболички тенгес, исправљена линеарна јединица (енг. rectified linear unit, ReLU) и накошена исправљена линеарна јединица (енг. leaky rectified linear unit, leaky ReLU). Формуле по којима се ове функције израчунавају и њихови графици приказани су на доњој слици. Као што можеш да приметиш, ове функције заиста нису линеарне - њихови графици нису праве.
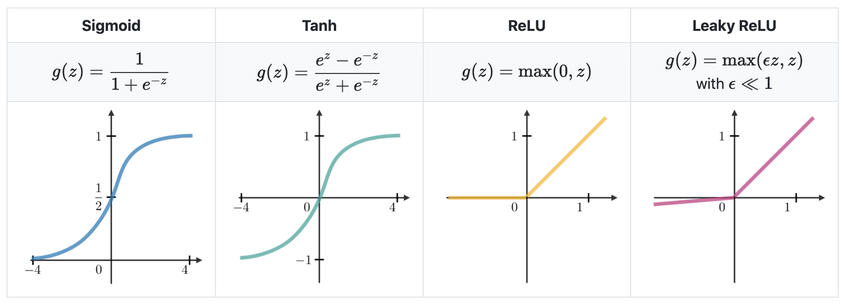
Најчешћи избори активационих функција
Да бисмо употпунили причу о комбиновању различитих активационих функција, посматрајмо функцијe \(f(x) = 2x\) и \(g(x) = 1-x\). Можемо да приметимо да су обе функције линеарне функције једне променљиве. Њиховим комбиновањем, композицијом функција, добијамо функцију \(g(f(x)) = 1-2x\), која је такође линеарна функција једне променљиве. Графике све три функције можемо да видимо и на доњој слици.
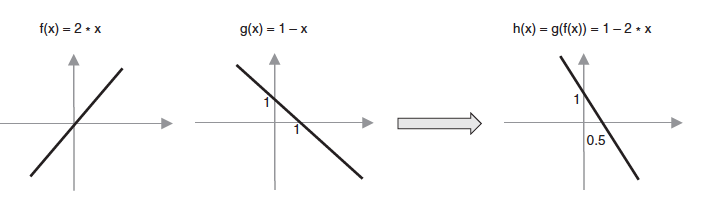
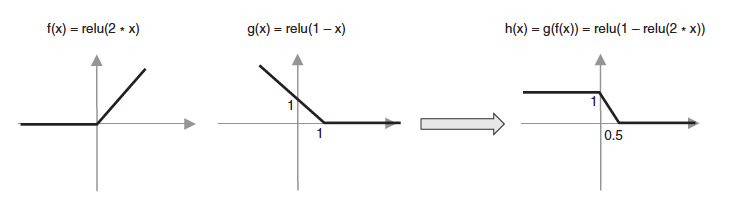
Посматрајмо сада функције \(f(x) = ReLU(2x)\) и \(g(x) = ReLU(1-x)\), које се од претходних функција разлику по томе што у њима фигурише активациона функција исправљена линеарна јединица. Зато су обе функције нелинеарне. Њиховим комбиновањем, тј. њиховом композицијом, добијамо функцију \(g(f(x)) = ReLU(1- ReLU(2x))\), која је такође нелинеарна и која има нови ”облик”: омогућава нам да изразимо нешто другачију зависност између улазне променљиве и излаза.
Избор одговарајуће активационе функције зависи од природе задатка и неких својстава које неуронска мрежа треба да има у току обучавања. Како се то ради, објаснићемо у следећој лекцији.