Механизам пажње и трансформери¶

Прича о ChatGPT-ју те сигурно није заобишла! Програм који може да извршава инструкције на говорном језику је заиста занимљив резултат. У позадини овог програма крије се дубока неуронска мрежа која се назива трансформер. У овој лекцији ћеш сазнати нешто више о трансформерима, као и о самој области која се зове обрада природних језика. Научићеш и како можеш да искористиш неке већ постојеће језичке моделе да би класификовао текст и генерисао кôд.
Међу примерима архитектура рекурентних неуронских мрежа видели смо да се за задатак машинског превођења користи енкодер-декодер архитектура. Енкодер има задатак да обради секвенцу на улазном језику и генерише векторску репрезентацију која може даље да је представља. Ту репрезентацију називамо контекстом. Декодер даље има задатак да на основу контекста, реч по реч, генерише одговарајући превод.
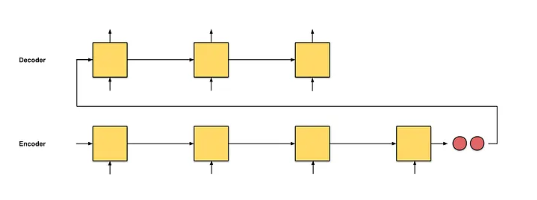
Архитектура енкодер-декодер
(слика је преузета са адресе https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3)
Људи преводиоци овај посао ипак реализују мало другачије, поготово ако су улазне секвенце нешто дуже. Они у процесу превођења не морају одједном да запамте целу реченицу, могу да застану, врате се на реченицу, обрате пажњу на осетљиве сегменте, на пример, време у реченици или коришћени предлог, и наставе са задатком превођења. Ова идеја која омогућава да се декодер у току генерисања садржаја не ослања само на информације из вектора контекста већ да може да се врати на улазну секвенцу и обрати нешто више пажње на важне делове је у основи такозваног механизма пажње (енг. attention mechanism).
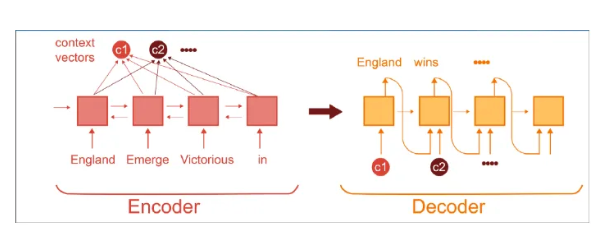
Енкодер-декодер архитектура са механизмом пажње: у сваком кораку генерисања декодер може да комбинује различите елементе улаза спрам њиховог значаја
Истраживачи су приметили да се овај механизам може искористити и за моделовање релација између елемената улаза и генерисање финијих репрезентације улаза. Рецимо, у доњој реченици, елемент (придев) green више доприноси разумевању својстава елемента (речи) apple него разумевању својстава елемента (речи) eating. Модификација оригиналног механизма пажње која нас доводи до оваквих репрезентација се зове самопажња (енг. self attention mechanism). Као резултат самопажње се за сваки елемент улаза добија одговарајућа векторска репрезентација - она представља елемент у контексту преосталих елемената улаза и њихових својстава. Зато за овакве репрезентације кажемо и да су контекстуализоване. Тако ће реч apple имати две различите репрезентације у двема различитим реченицама јер ће друге речи у реченицама утицати на њену репрезентацију. Пракса је и да се комбинује више механизама самопажње тако да сваки механизам самопажње може да моделује неко својство узлаза. На пример, један механизам самопажње може да се фокусира више на граматичка својства речи, други на интерпункцију, трећи на семантику и слично. Зато се често може чути да се говори о механизму самопажње са више глава (енг. multihead self attention).
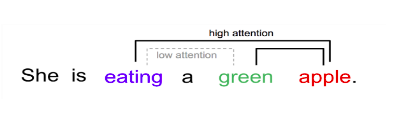
Мотивација за механизам самопажње
Механизам самопажње је у основи дубоких неуронских мрежа које се зову трансформери (енг. transformers). Трансформер се састоји из енкодера и декодера, а основа оба дела мреже су такозвани трансформер слојеви. Ми нећемо залазити у детаље ових блокова, али ћемо приближити смисао и функцију сваког од њих.
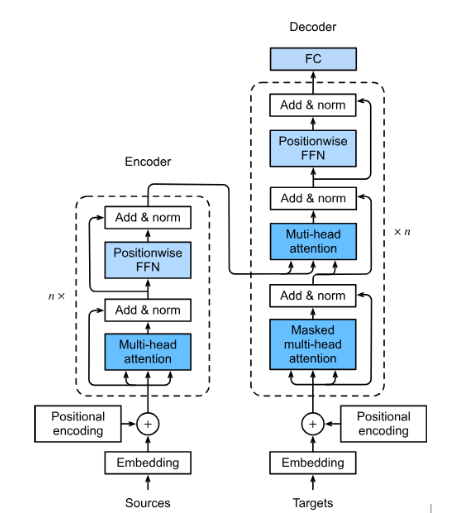
Трансформер
Улаз у енкодер део трансформера је фиксне дужине, обично 512 или 1024 елемента. Сваком елементу се засебно придружује вектор који има задатак да представља елемент у мрежи. Овај вектор се назива угњежђенa репрезентација елемента (енг. embedding) и у старту се насумично иницијализује. У току обучавања мреже ове репрезентације се профињују и уче, тако да могу адекватно да представе елемент у контексту других елемената. Уз репрезентацију, за сваки елемент улаза се трансформеру прослеђује и вектор који има задатак да представља позицију елемента у улазу. Мотивација за увођење вектора позиције лежи у идеји паралелизације. Због усаглашености израчунавања, важно је да вектор репрезентације и вектор позиције буду истих дужина.
Након улазног слоја у енкодеру се нижу такозвани трансформер слојеви. Они се састоје од механизма самопажње са више глава и једне потпуно повезане мреже са пропагацијом унапред. Други елементи који су саставни део ових трансформер слојева служе да одрже проток информација кроз мрежу и учине тренирање мреже стабилнијим. Баш као и у случају других мрежа, смисао овако увезених трансформер слојева је да се добије на комплексности апстрактних атрибута који се могу користити за решавање задатака. Обично је број трансформер слојева 6, 12 или 24 па трансформери резултирају великим бројем параметара који досежу и стотине милијарди.
И у декодер делу мреже се нижу трансформер слојеви. У њима постоји један механизам самопажње са више глава који прати сам ток рада декодера и други механизам самопажње са више глава који одржава везу са енкодером. Функција преосталих елемената слојева је, баш као и код енкодера, да усагласе демензије између различитих слојева, да одрже проток информација кроз мрежу, а потом и учине тренирање мреже стабилнијим. На излазу декодера је једна потпуно повезана мрежа чији се излази даље интерпретирају у складу са задатком.
Због великог броја параметара који треба да се науче, трансформери се обучавају кроз две фазе. У првој фази се користе такозвани припремни задаци (енг. pre-training tasks), док се у другој фази користе задаци профињивања (енг. fine-tuning tasks). Рецимо, трансформер BERT који је прославио ову архитектуру, као један од припремних задатака користи задатак маскирања речи: у улазу који треба проследити трансформеру насумично се маскира један број речи тако што се замени симболом [MASK], а задатак трансформера је да погоди које речи се крију иза маски. Важно је приметити да за овај задатак није потребан лабелиран скуп података па се може направити произвољно велики скуп за обучавање мреже избором насумичних реченица текстова и речи за маскирање у њима.
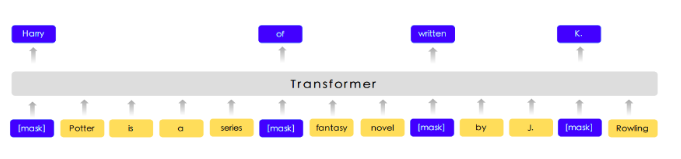
Задатак маскирања
Слично, модел GPT који је искоришћен као основа за ChatGPT, као припремни задатак користи погађања наредне речи: за задати низ речи задатак трансформера је да погоди наредну реч. Ни за креирање овог скупа података није потребно мануелно лабелирање, довољно је искористити произвољан скуп реченица.
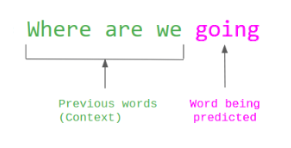
Задатак погађања наредне речи
У припремним задацима трансформери стичу нека општа знања. На пример, у случају трансформера који обрађују текст, то су знања о семантици и синтакси језика. Ова знања се даље могу унапредити додатним обучавањем трансформера на неким мануелно припремљеним скуповима података. Тиме се омогућава се они додатно прилагоде свом домену примене или неком конкретном задатку. Ова фаза обучавања трансформера се зове профињивање.
Први популарни трансформер са именом BERT развио je тим из компаније Гугл 2018. године за задатке обраде природних језика. Након њега су се појавиле варијанте модела које су могле да обрађују дуже улазе, да се брже тренирају, да раде са другим језицима и слично. Први у серији модела GPT осмислила је, такође 2018. године, компанија OpenAI. И овај модел је био повезан са обрадом природних језика. Касније су се појавили и трансформери за обраду слика, аудио-садржаја, мултимодални трансформери и други.

Велики број функционалности у раду са трансформерима нуди истоимена библиотека Transformers компаније Hugging Face. Уз развој библиотеке и алата, ова компанија се активно залаже и за отворено дељења модела. Највећи број њих може и да се тестира на званичном сајту https://huggingface.co у секцији Models. Ту можеш да испробаш како ради модел BERT, као и нека од доступних верзија модела GPT. Нешто касније ћеш научити и како да користиш ове моделе кроз кôд.
Обрада природних језика и велики језички модели¶
Први изазов са којим се сусрећемо у обради природних језика је представљање текста. Баш као и у случају слика, да би програми могли да обрађују текстуалне садржаје потребно је осмислити подесну нумеричку репрезентацију која у идеалном случају задржава сва лингвистичка и семантичка својства текста. Први покушаји креирања оваквих репрезентација су се заснивали на разбијању текста у низове речи. Тако се реченица енглеског језика „We like Python!” може разбити у низ „Wе”, „like”, „Python” и „!”. Овако издвојене речи називамо токенима, а саме програме који раде ова разбијања токенизаторима. За одређивање граница токена најчешће се користе белине и интерпункцијски карактери, али постоје и језици који не користе белине за раздвајање речи (такви су јапански, хинди, арапски и други). Добијену листу токена је могуће даље филтрирати, на пример, тако што се избаце интерпункцијски карактери или бројеви. Може се извршити и нормализација токена, на пример, свођењем свих токена на запис малим словима. У општем случају није лако одлучити шта је токен, а шта не. На пример, негација „don’t” се може третирати као један токен или као два токена „do” и „not”. Са друге стране, можда је природно да име града „New Yоrk” буде један токен, а не два. Многи домени попут друштвених мрежа или научних текстова имају и свој специфичан вокабулар па се поставља питање како представити неке баш доменски специфичне садржаје као што су скраћеница LoL или хемијскo име 4-Dimethylamino-2-hydroxy-benzoyl.
Сазнање о томе који се то све токени могу појавити у неком језику, тј. у неком конкретном домену или задатку, стиче се издвајањем свих токена у некој одабраној колекцији текстова (такве колекције називамо и корпусима). Овако издвојени токени, уређени лексикографски, представљају вокабулар. Сви садржаји се даље изражавају у терминима речи вокабулара. На пример, за реченицу ”We like Python!” генерише се репрезентација која представља вектор нула чија дужина одговара дужини вокабулара и која само на позицијама које одговарају речима „Wе”, „like”, „Python” и „!” има јединице. Уместо јединица се на овим позицијама могу уписивати и вредности које узимају у обзир фреквенције појављивања речи у улазу, дужине реченица као и статистичке информације из самог корпуса. Овакве репрезентације се једним именом зову вреће речи (енг. bag of words).
Овакве репрезентације су једноставне за креирање и послужиле су у првим данима развоја система за претраживање информација и обраде текста. Ипак, ове репрезентације су изразито дуге (број речи у вокабулару може да досеже и неколико десетина хиљада), ретке, тј. са малим бројем вредности које су разлучите од нуле и приликом њиховог креирања се губи информација о редоследу речи у улазу. Зато се у новије време, када то дозвољавају ресурси и задаци, користе репрезентације које су засноване на неуронским мрежама. Ове репрезентације су значајно краће (дужине неколико стотина) и компактније, али њихово значење више није лако разумети. Овакве репрезентације зовемо угњежђеним репрезентацијама.
Word2Vec је име технике која је прославила представљање текстуалних садржаја угњежђеним репрезентацијама. У основи ове технике је неуронска мрежа која је креирана тако што је на основу суседних речи погађала која реч недостаје. Испоставило се да овако добијене репрезентације речи имају врло занимљива семантичка својства. Вероватно је напознатији пример у вези са репрезентацијама речи онај који се односи на речи king и queen: уколико се од репрезентације речи king одузме репрезентација речи man, а затим се на овако добијену разлику дода репрезентација речи woman, добиће се репрезентација која одговара речи queen.
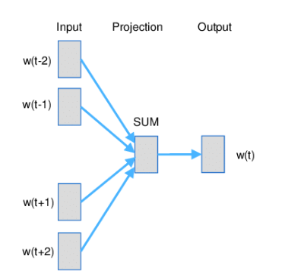
Word2Vec и архитектура континуална врећа речи (CBOW)
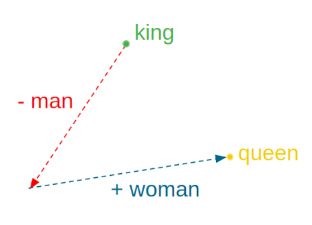
Пример аритметичких операција у простору угњежђених репрезентација
У раду са трансформерима текст се најчешће представља парчићима речи (енг. wordpiece tokenization) или парчићима бајтова (енг. byte-pair encoding). Парчићи се пажљиво издвајају проласком кроз неку велику колекцију текстуалних садржаја и бирају тако да се њиховим комбиновањем може реконструисати највећи део текста. Издвајање и одабир парчића се не ради ручно, већ се за те задатке користе посебни алгоритми. Издвојени парчићи се, без обзира на алгоритам који је коришћен, називају токенима и сви скупа представљају вокабулар једног трансформера.
Уобичајено је да се трансформери који раде са текстуалним подацима називају језички модели (енг. language models). С обзиром на то да је реч о дубоким неуронским мрежама са великим бројем параметара, обично се за ове моделе каже и да су велики па се на њих реферише са велики језички модели (енг. Large Language Models, LLMs). У наставку ћемо упознати неке такве моделе и опробати се у задацима анализе сентимената у тексту и генерисања кода.
Анализа сентимената у тексту¶
Задатак анализе сентимената (енг. sentiment analysis) је задатак препознавања емоција или ставова присутних у неком тексту. Само препознавање је доста базичније у односу на људе, али има своју важну улогу у разумевању кориснички генерисаних садржаја попут коментара или прегледа. Најчешће се сусрећемо са задатком препознавања позитивних и негативних садржаја где позитивни садржаји означавају нешто похвално и лепо а негативни садржаји критике и замерке. Самом задатку анализе сентимената из угла машинског учења приступамо као задатку бинарне класификације: након што припремимо адекватно репрезентације текстуалних улаза, можемо применити било који алгоритам класификације. Садржај се, наравно, може анализирати и на финијој градацији сентимента која уз позитивне и негативне одреднице има и одреднице попут врло позитивно, неутрално или врло негативно.

Ова секција је упарена са Jupyter свеском 10-transformeri_i_jezicki_zadaci.ipynb.
Да би могао да пратиш садржај даље, кликни на линк, а потом и на дугме  да би се садржај отворио у окружењу Google Colab.
Уколико свеске прегледаш на локалној машини, међу садржајима пронађи свеску са истим именом и покрени је. За детаљније инструкције
погледај секцију Hands-on зона и лекцију Jupyter свеске за вежбу.
да би се садржај отворио у окружењу Google Colab.
Уколико свеске прегледаш на локалној машини, међу садржајима пронађи свеску са истим именом и покрени је. За детаљније инструкције
погледај секцију Hands-on зона и лекцију Jupyter свеске за вежбу.
Кôд кроз који ћемо проћи је садржан у пратећој свесци. Свеска садржи још неке примере који ти могу бити занимљиви и који ти могу појаснити процес рада са трансформерима.
За задатак анализе сентимената користићемо библиотеку transformers, која обједињује различите врсте трансформера и алате који омогућавају удобнији рад са њима. Да би ова
библиотека могла да се користи у окружењу Google Colab, потребно ју је инсталирати наредбом !pip install transformers а потом и учитати наредбом import transformers.
!pip install transformers
import transformers
Следећи блок кода ће нам омогућити да креирамо функционалност analiziraj_sentiment, која за нас обједињује кораке креирања репрезентације текста а потом и покретања већ обученог
класификатора за анализу сентимената. За њено креирање искористићемо функцију pipeline и посебно аргументом task нагласити да желимо да се бавимо анализом сентимената.
analiziraj_sentiment = transformers.pipeline(task='sentiment-analysis')
Учитаној функционалности можемо да задајемо улазе за које желимо да добијемо оцену сентимента. Као излаз ћемо добити име класе POSITIVE или NEGATIVE, као и вредност score у интервалу од 0 до 1, која указује колико је модел класификације сигуран у своју одлуку. Следи неколико примера. Изврши их па промисли да ли би се и ти сложио са одлукама класификатора.
analiziraj_sentiment("We are very excited to learn more on sentiment analysis!")
analiziraj_sentiment("We didn't like the food. It was too salty.")
analiziraj_sentiment("The movie was super interesting, but the end was quite boring.")
Док је емоција усхићења, тј. недопадања била прилично јасно изражена у првим двема реченицама које смо тестирали, у трећој реченици имамо занимљиву мешавину. Можеш да наставиш даље да тестираш ову функционалност тако што ћеш проверити како на одлуке класификатора утичу придеви попут amazing, wonderful, boring, annoying и њихова комбинација. Можеш да провериш и како се класификатор понаша када је у реченици присутна негација, на пример, када кажеш да нешто није сјајно.
Највећи број језичких модела је развијен за енглески језик. На овакав статус су утицали многи фактори о којима смо дискутовали у току курса. Пре свега, доступност расположивих садржаја и велика језичка заједница. Међу моделима који су доступни у библиотеци Transformers можеш да пронађеш и моделе који се односе на српски језик, који су примарно креирани у академском окружењу. Неки од њих су bcms-bertic и sr-gpt2-large.
Генерисање кода¶
Трансформерима се у току обучавања могу проследити и садржаји на програмским језицима. Резултат таквих експеримената су модели који могу да асистирају у току програмирања тако што допуњавају кôд, преводе га са једног програмског језика на други, генеришу кôд на основу задатих смерница или пишу документацију. Међу првим моделима ове врсте је био модел Codex који се налазио у позадини сервиса GitHub Copilot. Поред модела Codex (који се, необично, већ сматра застарелим), ту су и модели CodeBERT, CodeParrot, InCoder, PolyCoder, AlphaCode, CodeGen и други. Уз ове моделе могу се користити и неки велики језички модели који уз језичке задатке умеју да покрију и програмерске задатке. Такви су, рецимо, модели попут GPT-3.5 и његових наследника и BART.
За све поменуте моделе је заједничко да у основи имају трансформер архитектуру. Њихове дубине и бројеви параметара ипак варирају па тако модел CodeParrot има 1,5 милиона параметара, а модел CodeGen 16,1 милиона. За њихово обучавање су коришћени отворени репозиторијуми платформе GitHub, садржаји са платформи као што су Stack Overflow и Stack Exchange, садржаји са такмичарских платформи и други скупови који се односе на различите програмске језике. За тестирање ових модела користе се, такође, специјално припремљени скупови података. Они садрже промптове, блокове кода који описују задатке, и очекиванa решења. Један такав скуп је и HumanEval креиран за потребе тестирања модела Codex. На слици испод можеш да видиш неке задатке овог скупа, тј. промптове који их карактеришу и очекивана решења (она су обојена жутом бојом).
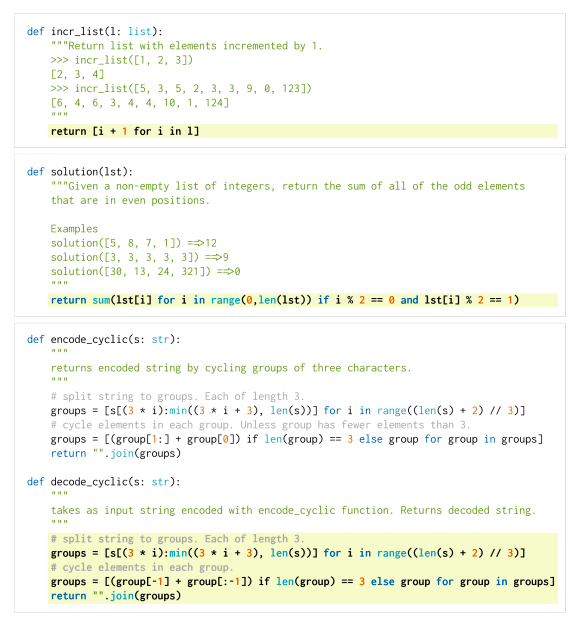
Примери промптова скупа HumanEval
Сваки од модела који смо поменули је заиста велики и у погледу меморије коју захтева за преузимање и чување. Зато је најбоље да се у овим задацима опробаш преко неког веб-интерфејса. Велике језичке моделе попут ChatGPT-јa или BART-a можеш користити уз претходно отварање налога. На платформи Hugging Face, у секцији Models, један број модела можеш да тестираш уносом кода у прозор за тестирање са десне стране. Иако занимљиви за експериментисање, ови прозори не остављају много могућности за подешавање модела. За неке моделе постоје и посебни сервиси за тестирање који дозвољавају више конфигурација. Такав је, рецимо, сервис CodeParrot доступан на адреси https://huggingface.co/spaces/codeparrot/codeparrot-subspace.
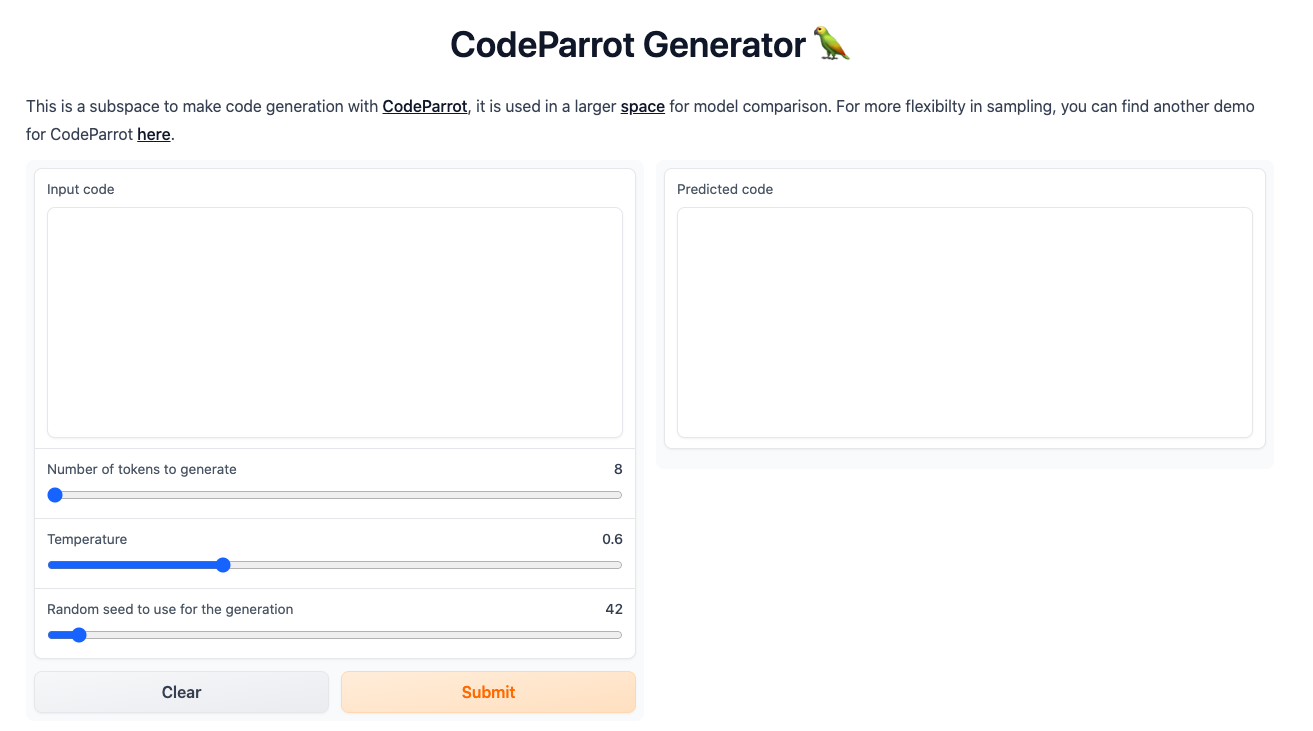
Интерфејс сервиса https://huggingface.co/spaces/codeparrot/codeparrot-subspace
Сервис CodeParrot дозвољава да се контролише дужина генерисаног излаза (параметар Number of tokens to generate), процес избора наредног токена (параметар Temperature) и случајност генерисања (параметар Random seed to use for the generation). Ово су три параметра која ћеш сусретати и у другачијим окружењима. Дужина излаза и контрола случајности, за коју смо рекли да нам је важна због поновљивости резултата, сасвим су интуитивни параметри па ћемо се задржати на појашњењима параметра температуре.
Приликом генерисања велики језички модели за све токене у вокабулару израчунавају вероватноће појављивања токена у улози наредног токена. Можемо да замислимо да имамо 5 токена и да је израчуната вероватноћа за сваки од токена приказана графиком на левој страни доње слике. Уколико повећамо вредности параметра температуре, утицаћемо да ова расподела вероватноћа буде праведнија, налик на приказ који видимо са десне тране слике. Што је вредност температуре већа, то ће токени имати равноправнији утицај, и обратно, што је температура мања (најмања вредност је 0), то смо ближи оригиналним израчунавањима модела. У контексту генерисања, за мале вредности температуре модел бира токене око којих је ”сигурнији”, док је код већих вредности температуре слободнији и ”креативнији”.
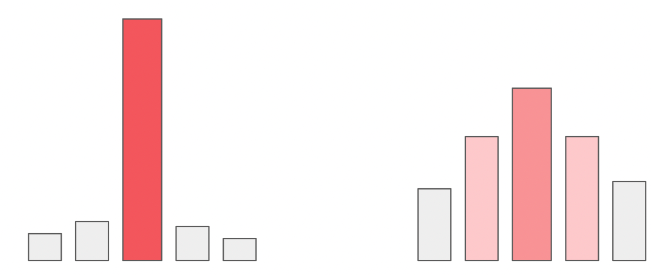
Утицај температуре на избор наредног токена
Сада можеш да тестираш рад овог сервиса тако што ћеш задати неки свој промпт или искористити неки од промптова које сервис већ нуди: def print_hello_world():, def count_lines(filename): и def get_file_size(filepath):.
Најбоље је да упоредиш резултате који ће ти дати више модела и стекнеш утисак шта су изазови приликом генерисања кода. Имај на уму да ове сервисе бесплатно употребљава већи број корисника и да се може десити да у неком тренутку нису доступни.